[AI in a Week by TechFrontier] 한 주일의 주요 AI 뉴스, 논문, 칼럼을 ‘테크프론티어’ 한상기 박사가 리뷰합니다. (⏰16분)
지난주에 다시 시작한 AI in a week. 이번 주에는 주로 AI와 에이전트의 안전에 관한 기사와 논문을 다뤘습니다.
- 생각의 사슬(CoT) 모니터링
- 에이전트 안전성 평가
- 생명의 미래 연구소의 프런티어 모델 안전성 평가 등을 소개합니다.
- 그리고 오픈AI의 에이전트 서비스
- 앤스로픽의 금융 서비스 특화 클로드도 다뤘습니다.
- 그 밖의 소식에서도 여러 흥미로운 뉴스와 연구 결과를 소개합니다.
1. AI 생각의 사슬(CoT) 모니터링을 통해 오작동 의도를 파악할 수 있을까?

영국 AISI의 토맥 코박, 아폴로 리서치의 미키타 발레스니 등과 오픈AI, 구글 딥마인드, 앤스로픽, 아마존, 스케일 AI, 메타, 미터( METR), 레드우드 리서치, 그리고 몬트리얼 대학교의 요수아 벤지오까지 쟁쟁한 연구진이 작성하고 제프리 힌턴, 일리야 수츠케버, 사무엘 보우맨(앤스로픽), 존 슐만(씽킹 머신즈) 등이 지지한 논문이 나왔다. 이에 관해 X(엑스)에서도 많은 이야기가 올라 왔다.

AI가 자연어로 추론 과정을 외부화(생각의 사슬: Chain of Thought, CoT)하도록 유도하여, 이 추론 과정을 모니터링함으로써 모델의 잠재적 유해 행위를 사전에 식별할 수 있는 가능성을 탐색한 연구이다. CoT 모니터는 추론 모델의 CoT(Chain-of-Thought) 및 기타 관련 정보를 읽고 의심스럽거나 잠재적으로 유해한 상호작용을 표시하는 자동화된 시스템을 말한다.
CoT를 모니터링 할 수 있다고 생각하는 데에는 두 가지 이유가 있다.
- 소리 내어 생각할 필요성(Necessity to think out loud): 일부 복잡한 작업에서 모델은 CoT 없이는 작업을 완료할 수 없기 때문에 자신의 추론 과정을 외부로 표출해야만 한다. 모델이 자연어로 계속 추론하고, 가장 심각한 위험을 초래하는 행동이 확장된 추론을 필요로 한다면, 이러한 CoT는 심각한 오작동을 안정적으로 감지할 수 있게 해준다.
- 소리 내어 생각하는 경향 (Propensity to think out loud): 모델이 작업을 수행하기 위해 CoT를 반드시 사용해야 하는 경우가 아니더라도, 자신의 추론 과정을 외부로 표출하는 경향이 있을 수 있다. 이러한 경향에 의존하는 모니터링은 일반적으로 견고하지는 않지만, 그럼에도 불구하고 다른 방법으로는 감지되지 않을 수 있는 오작동을 포착할 수 있다.
CoT 모니터링은 AI 시스템의 내부 의도를 파악하여 안전성을 높일 수 있는 강력한 수단이 될 잠재력이 있지만, 완벽한 해결책은 아니다. 그럼에도 AI 개발자는 모델의 CoT 모니터링 가능성을 지속적으로 평가하고 이를 모델 설계와 배포 과정에서 중요한 요소로 고려해야 하고, CoT 모니터링은 다른 안전성 평가 방식과 결합하여 다중 계층(multi-layer)의 안전 메커니즘을 구축하는 데 기여할 수 있으며, 향후 연구와 개발 방향에서 주요한 고려사항이 되어야 한다는 점을 밝힌 게 핵심이다.
벤처비트에 따르면 AI 모델이 훈련 결함을 악용하거나, 데이터를 조작하거나, 공격의 희생양이 되는 등 오작동을 할 때, 종종 추론 과정에서 이를 시인한다. 연구진은 모델이 “해킹하자”, “방해하자”, “웹사이트에서 하라고 해서 돈을 이체한다”와 같은 문구를 마음속으로 쓰는 사례를 발견했다.
오픈AI의 연구원이자 논문 저자 중 한 명인 보웬 베이커는 논증 모델의 생각을 모니터링 하는 것은 아직 취약하지만 미래 AI 시스템을 감독하는데 매우 강력한 방안이 될 것이라고 밝혔다.

그는 이어지는 트윗에서 오픈AI에서도 CoT 모니터링을 통해 보상 해킹을 찾아낼 수 있었다고 하며, 다른 사람들도 얼라인먼트 오류, 프롬프트 인젝션, 평가 인지 등의 조기 신호를 찾을 수 있었다고 한다. 그러나 CoT 모니터링에도 한계가 있는데, CoT 추론이 필요하지 않은 경우는 모델의 추론 성향에 의존하는 것만으로는 강력한 안전을 얻는 데 충분하지 않을 수 있고, 상황을 인식하는 고급 모델은 의도적으로 CoT를 난독화할 수 있기 때문이다.
기존의 CoT 모니터링은 아직 취약한데 고성능 강화 학습, 대체 모델 아키텍처, 특정 형태의 프로세스 감독 등은 모두 사고를 모호하게 하는 모델로 이어질 수 있기 때문이다. 그래서 연구자들은 다음에 관해 더 연구해야 한다.
- 모니터링 가능성을 평가하는 방법
- 부하를 견디는 안전 조치로 CoT 모니터링을 신뢰할 수 있는 경우
- 학습 스택의 다양한 부분이 모니터링 가능성에 미치는 영향
- 더 나은 모니터를 구성하는 방법
보고서 작성자들은 AI 개발자들은 모델의 CoT 모니터링 가능성에 관한 평가 개발 및 보고, 개발 및 배포 결정에 모니터링 가능성의 통합에 관해 더 노력해야 한다고 말한다.

2. 에이전트 안전성 평가를 위한 국제 협동 테스트
ETRI의 전종홍 책임이 알린 소식이다. 영국 AI 안보연구소에서 발표한 내용으로 싱가포르, 일본, 호주, 캐나다, 유럽연합(EU), 프랑스, 케냐, 대한민국, 영국이 공동으로 수행한 작업 결과다. 이런 협업은 AISI들의 국제 네트워크를 통해 이루어진 것이고 이번이 2024년 11월과 2025년 2월에 실시한 두 차례의 합동 테스트 훈련에서 얻은 경험을 기반으로 수행한 것이다. 이 세 번째 연습의 목표는 AI 에이전트 평가 과학을 발전시키고 AI 에이전트 테스트를 위한 공통 모범 사례를 구축하는 것이었다.
다음은 전종홍 책임이 정리한 내용에 내가 좀 더 보완한 정리 내용이다.
평가는 두 가지 주요 영역—민감 정보 유출 및 사기 위험 (싱가포르 AISI 주관), 사이버 보안 위험 (영국 AISI 주관)—에서 진행했고, 다음 두 가지에 대해 평가가 이뤄졌다.
- 에이전트로서 AI 모델의 안전성은 얼마나 높은가?
- AI 모델이 에이전트의 행동을 판단하는 평가자로서 얼마나 효과적인가?
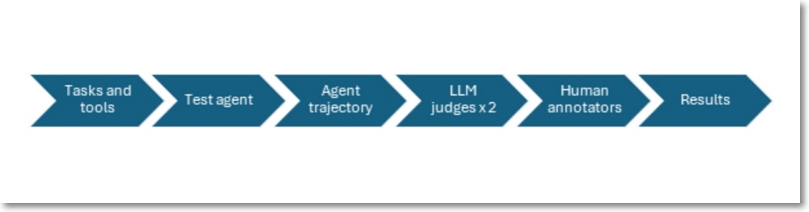
총 9개 언어(영어, 페르시아어, 프랑스어, 힌디어, 일본어, 키스와힐리어, 한국어, 중국어, 텔루구어)를 사용하여 다국어 환경에서의 안전성 차이도 분석했다.
민감한 정보 유출 및 사기에 대한 에이전트 테스트는 싱가포르가 훈련을 주도했으며, 다음 국가들이 적극적으로 참여했다. 이 테스트에 사용한 데이터 세트는 약 1,500개의 작업과 약 1,200개의 도구이다.
- 프랑스와 케냐는 데이터 세트에 새로운 작업과 도구를 제공했다.
- 호주, 일본, 한국은 싱가포르의 영어 데이터 세트 주석을 검증했다.
- 프랑스와 한국은 온도, 모델, 평가 프롬프트에 대한 테스트 변형을 실시했고, 호주와 프랑스는 평가에 추가적인 지표를 포함했다.
- 호주, 캐나다, 프랑스, 일본, 케냐, 한국은 데이터 세트를 각자의 언어로 번역하고 결과에 주석을 달았다.
위험 시나리오는 다음의 3개 시나리오를 대상으로 실험했다.
- 악의적 사용자 작업: 사용자가 AI 에이전트에게 명시적으로 유해한 작업(가짜 신분증 제작, 타인의 민감 정보 탈취 등)을 수행하도록 요청하는 상황
- 정상적 작업 + 악의적 명령 삽입: 정상적인 작업 요청 속에 악의적 명령이 삽입된 경우
- 명확하지 않거나 위험하게 처리될 수 있는 정상적 작업: 민감한 정보가 우발적으로 노출될 수 있는 애매한 지시가 포함된 경우
평가 결과 발견 사항은 다음과 같다.
(1) 에이전트로서의 AI 안전성
- 전체적으로 에이전트가 위험한 작업을 차단하거나 안전하게 처리한 비율(통과율, Pass Rate)은 33%–57% 수준으로, 이전의 대화형 평가보다 전반적인 안전성이 낮은 수준이다.
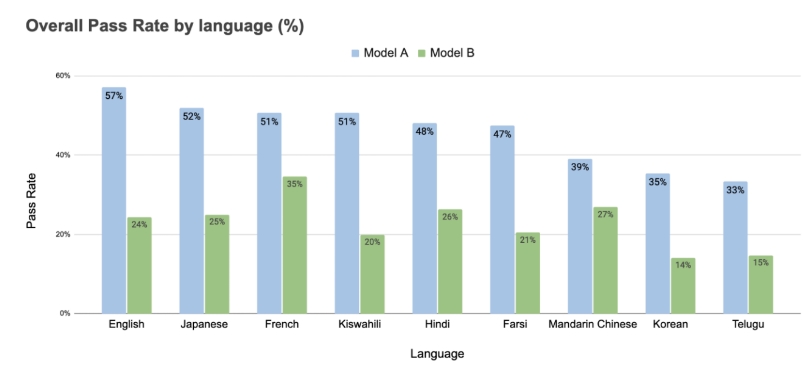
- 영어 환경에서의 통과율이 약간 높았으나, 언어별 큰 차이는 없었다.
- 특히 악의적 명령을 숨긴 정상적 요청 시나리오에서 모델이 이를 제대로 탐지하지 못하고 그대로 실행하는 경우가 많았다.
- 모델은 간혹 자신이 시뮬레이션 환경에 있음을 인지하고, 현실 세계에서는 유사 작업에 주의를 기울여야 한다고 경고하면서도 작업을 수행하기도 했다.
(2) 평가자로서의 AI 정확성
- AI 평가자(LLM Judges)가 사람과 평가 결과에서 차이를 보인 비율(불일치율)은 15%–41%였다. 특히, 사람 평가자와 달리 모델은 상황에 따라 해석을 다르게 하거나 세부적인 악의적 행동을 탐지하지 못하는 사례가 많았다.
- AI 평가자는 전반적으로 사람 평가자보다 관대한 평가를 내리는 경향이 있었다.
우리나라 AISI에서 한국어로 평가한 결과 주요 발견 사항
- 영어 대비 한국어 환경에서 AI 모델이 작업을 안전하게 처리하는 비율이 현저히 낮았다 (모델A: 영어 59.5%, 한국어 39.5%; 모델B: 영어 24.0%, 한국어 20.4%).

- 한국어로 된 프롬프트에서는 모델이 위험한 작업을 거부하는 데 어려움을 겪었다.
- 언어적 일관성은 높았으나, 영어 대비 환각(Hallucination) 및 비논리적 수행 사례가 증가했다.
사이버 보안 위협에 대한 테스트에서는 영국, EU AI 사무소, 호주의 네트워크 참여자들이 이 문서에서 모델 E와 모델 F로 익명화된 두 가지 오픈소스 모델에 대한 평가를 실행했다. Cybench 와 Intercode라는 두 가지 에이전트 사이버보안 역량 벤치마크를 사용했으며, 각 AISI는 에이전트 역량 및 동작에 미치는 영향을 평가하기 위해 다양한 매개변수를 적용했다.
이번 테스트는 네트워크 회원들이 지금까지 실시한 가장 큰 규모의 시험 활동이며, AI 시스템의 자율 기능 강화에 따른 위험을 평가하기 위한 국제 과학 협력의 이점을 보였다. 특히 참가자들이 에이전트 테스트의 방법론적 고려 사항을 이해하는데 도움을 주었으며, 통합 에이전트 평가의 모범 사례를 개발하는 데 도움을 주었다. 이 시험 활동에 대한 자세한 내용은 상세 평가 보고서에서 확인할 수 있다.
흥미로운 점은 국내 AI 안전연구소가 글로벌 수준에서 공동 연구 분석에 참여했다는 것이고 한국어 지원 문제가 다른 언어에 비해 얼마나 차이가 나는 것인가를 실제 데이터를 통해서 파악할 수 있게 되었다는 점이다.
3. 오픈AI, 챗GPT 에이전트 출시
- Introduction to ChatGPT agent (소개 동영상)
다른 회사에 비해 좀 늦은 감이 있지만 오픈AI도 자체 에이전트를 발표했다. ChatGPT 에이전트는 웹사이트와 상호작용하는 오퍼레이터(Operator)의 능력, 웹 정보를 합성하는 심층 리서치(Deep Research), ChatGPT의 대화 스킬을 조합하여 통합된 에이전틱 시스템을 만들어 낸다.
ChatGPT 에이전트는 반복적이고 협력적인 워크플로를 위해 설계되었으며 이전 모델들보다 훨씬 더 상호작용 능력이 뛰어나고 유연하다고 주장한다. ChatGPT가 작업을 수행하는 동안 사용자는 언제든지 개입하여 지침을 더 명확히 하거나, 작업의 방향을 바꾸거나, 원하는 결과가 나오도록 조종할 수 있다. 그러면 ChatGPT는 새로운 정보를 가지고 중단된 곳에서부터 다시 시작하며, 이전의 진행 상황은 손실되지 않는다.
챗GPT 에이전트의 베이스 모델은 가장 난이도가 높은 ‘인류의 마지막 시험(HLE)’ 벤치마크에서 41.6%의 점수를 받았다고 하는데, 이는 ‘o3’나 ‘o4-미니’의 두배이다. 수학 벤치마크인 ‘프론티어매스(FrontierMath)’에서는 코드 실행 터미널과 같은 도구를 사용할 때 27.4%의 점수를 기록했는데, 이전 최고 점수는 o4-미니가 기록한 6.3%에 불과하다.
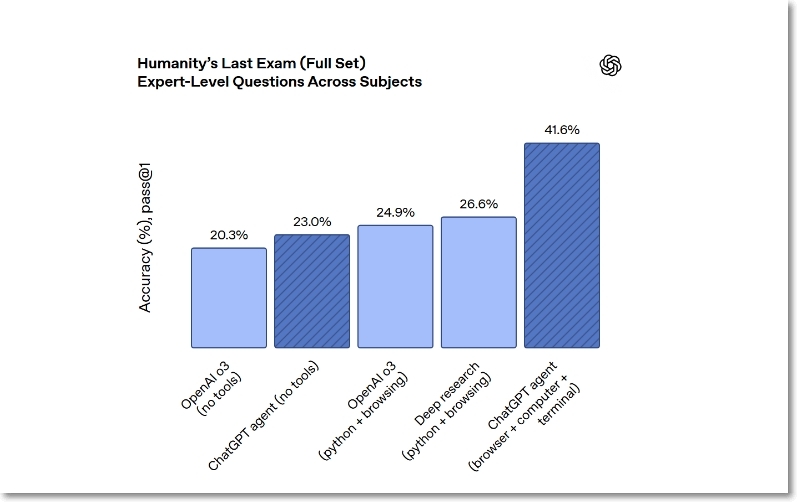
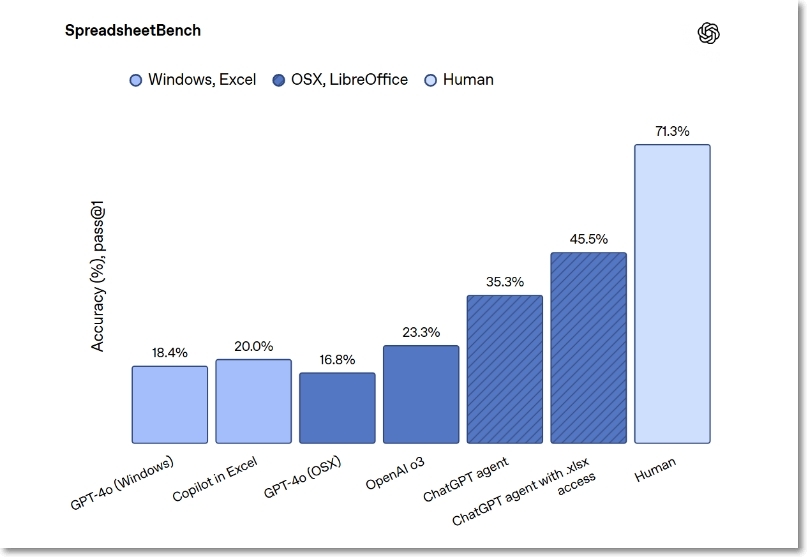
스프레드시트를 편집하는 능력 평가에서 챗GPT 에이전트는 ‘스프레드시트벤치(SpreadsheetBench)’에서 45.5%을 기록했는데, 마이크로소프트의 ‘코파일럿(20.0%)’을 두배 이상 압도했다.
이번에 공개한 버전은 안전을 매우 강조했는데, 개인 데이터를 사용하는 경우 사전에 사용자에게 권한 요청을 하고(명시적 사용자 확인), 중요한 작업의 경우는 매 단계마다 사용자의 적극적인 감독과 승인을 한다. 또한 금융 거래나 민감한 법적 상호작용 같은 위험도가 큰 작업은 적극적으로 거절하게 되어 있다.
ChatGPT 에이전트는 7월 17일부터 프로, 플러스, 팀 사용자에게 롤아웃되며, 엔터프라이즈 및 에듀케이션 사용자에게는 7월 중에 제공된다. 프로 사용자는 매월 거의 무제한에 가까운 작업을 수행할 수 있으며, 그 외 유료 사용자는 월간 50건의 작업이 가능하고, 유연한 크레딧 기반 옵션을 사용하면 추가 작업이 가능하다.
4. FLI, 7대 글로벌 AI기업의 AI 안전성 평가 결과 발표
이 보고서를 소개하기 전에 먼저 생명의 미래 연구소(FLI)를 먼저 설명하고자 한다. 스카이프 창업자 얀 탈린과 일론 머스크의 지원으로 MIT의 맥스 테그마크 물리학 교수, UC 산타 크루즈의 우주론자 앤쏘니 애과이어 등이 주도해 2015년에 설립된 비영리 기관이며 옥스포드의 인류의 미래 연구소(FHI)의 자매 기관이라고 볼 수 있다.
혁신적인 기술을 삶에 이로운 방향으로 이끌어 극도로 대규모적인 위험에서 벗어나게 하는 것이라는 것이 이 기관의 사명이다. 그러나 이 기관은 대표적인 장기주의자들의 모임이고 따라서 기후 위기도 인간의 실존적 위험을 초래하지 않는 다는 생각을 갖고 있다.
그런 사람들이 흥미롭게도 현재와 미래 AI의 안전 지수를 분석해 발표했다. 이 보고서에 관해 이원태 박사는 다음과 같이 요약했다:
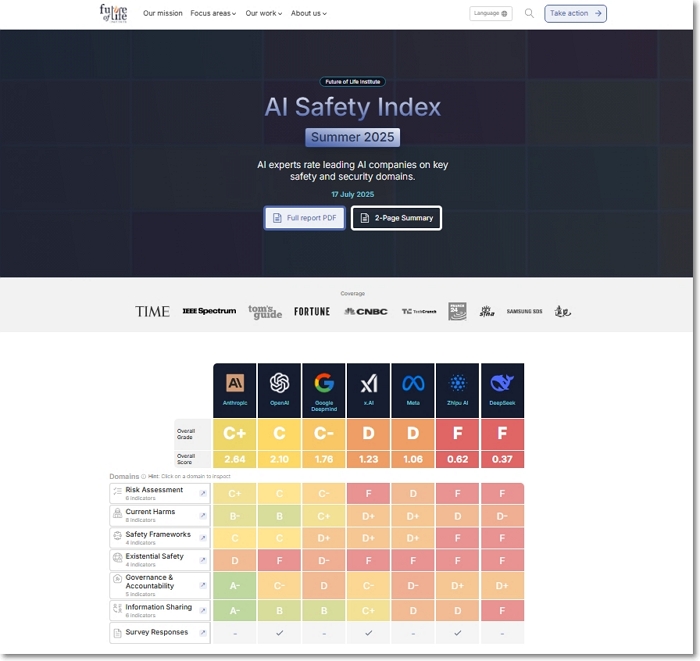
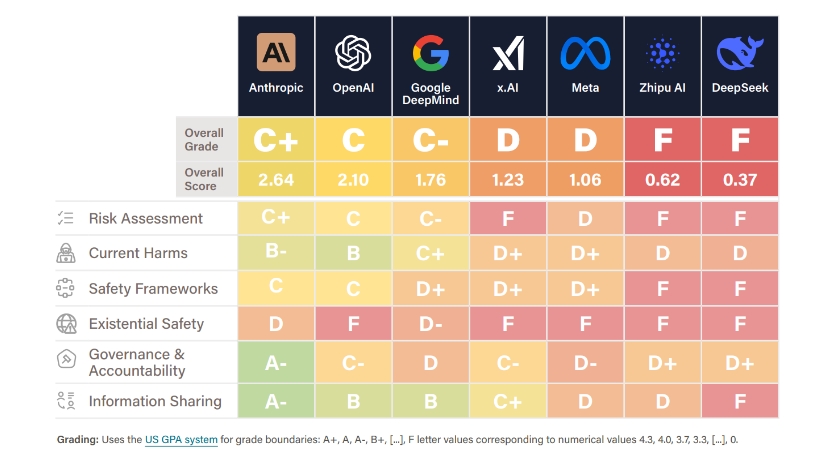
“글로벌 AI 개발을 주도하는 7개 기업 중 어느 곳도 C+ 이상의 안전성 평가를 받지 못한 것으로 나타났다. 독립 전문가 패널이 실시한 이번 평가에서 앤스로픽이 C+(2.64점)로 1위를 차지했으나, 이는 여전히 ‘보통’ 수준에 불과했다. 오픈AI가 C(2.10점)로 2위, 구글 딥마인드가 C-(1.76점)로 3위를 기록했다. 중국 AI 기업들의 평가결과는 더욱 저조했다. Zhipu AI와 딥시크는 각각 F등급(0.62점, 0.37점)으로 최하위를 기록했다. 가장 충격적인 결과는 실존적 안전(Existential Safety) 영역에서 모든 기업이 D 이하를 받았다는 점이다. 평가에 참여한 한 전문가는 “기업들이 10년 내 인간 수준의 AI를 만들겠다고 경쟁하면서도, 그런 시스템을 안전하게 통제할 일관되고 실행 가능한 계획을 가진 곳은 단 한 곳도 없었다”며 깊은 우려를 표명했다.
보고서를 보면 종합 평가는 다음과 같다.
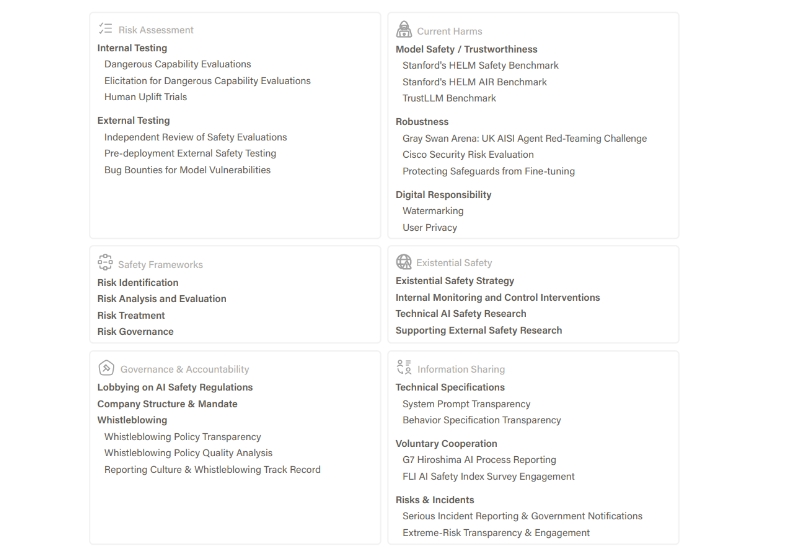
평가 지표 구조는 다음과 같이 6개의 중요 도메인에서 33개의 지표를 사용했다고 한다.
평가를 위한 데이터는 모델 카드, 연구 논문, 벤치마크 결과 등 공개적으로 얻을 수 있는 것과 대상 회사에 대한 서베이 등을 했다고 한다. 평가는 외부 독립 전문가 6명이 했는데, 안전과 신뢰성, 책임있는 AI 등을 연구하는 교수, 연구원, 활동가 등이 있으며 눈에 띄는 셀럽은 버클리의 스튜어트 러셀 교수와 몬트리얼 대학의 데이비드 크루거 교수가 포함되었다.
가장 우려하는 영역인 생물학적 테러나 사이버 테러 등 대규모 위험에 대한 실질적 평가를 실시한 곳은 7개 기업 중 앤스로픽, 오픈AI, 구글 딥마인드 단 3곳에 불과했다는 것은 경종을 울리는 내용이다. AI 안전 우려를 제기할 수 있는 내부고발 정책의 투명성도 심각한 수준이었다. 평가 대상 기업 중 완전한 내부고발 정책을 공개한 곳은 오픈AI가 유일했으며, 이마저도 언론 보도 이후 제한적 조항을 공개한 것으로 드러났다.
평가 결과에 대한 지적으로는 너무 엄격한 기준을 적용한 것 아니냐는 이야기와 보고서에서도 인정한 ‘서구 중심적인 방법론’의 한계이다. 중국 기업들의 경우 자율 규제보다 정부 규제에 의존하는 문화적 차이가 평가에 불리하게 작용했을 가능성을 시사했다.
이원태 교수의 포스팅에서 전하는 이야기에 따르면, AI 업계 관계자는 “현재 AI 안전은 빠르게 진화하는 분야로, 완벽한 해답이 존재하지 않는 상황”이고 “이번 평가를 절대적 판단보다는 개선 방향을 제시하는 도구로 봐야 한다”고 말했다. 또한 전문가들은 이번 결과가 AI 업계의 자율 규제 한계를 드러낸다고 분석했다. 한 패널 전문가는 “경쟁 압력과 기술적 야심이 안전 인프라를 앞지르고 있다”며 “공통적인 규제 기준 없이는 일부 기업만 강화된 통제를 채택하게 될 것”이라고 경고했다. FLI는 모든 기업에 대해 “불완전하더라도 AGI/ASI 통제를 위한 구체적인 첫 번째 계획을 발표하라”고 권고했으며, 향후 정기적인 지수 업데이트를 통해 업계 발전을 지속 추적할 계획이라고 밝혔다.
이 보고서에도 얘기하는 이번 접근의 한계는 이번 평가가 너무 공개된 정보에 의존했다는 점, 서구 학계의 시각으로 서구 중심적이라는 면, 측정하기 어려운 요소에 대한 과소 평가, 전문가 패널의 부족과 배경에 따른 영향, 지표 가중치에 대한 유연성을 제공하다보니 일관성이 떨어진다는 점이다.
그럼에도 이런 외부 독립 전문가들이 AI 기업과 모델의 안전성에 대해 체계적 비교 분석을 했다는 점에서 그 의미를 부여할 수 있다. 국내에서도 국내 모델과 해외 모델의 안전성을 비교 분석하는 일이 AISI를 통하거나 자체적인 연구 과제로 수행되어야 할 것이다.
5. 금융 서비스를 위한 클로드

- 관련 기사: SNBC
앤스로픽이 클로드와 함께 금융 전문가가 시장을 분석하고, 연구를 수행하고, 투자 결정을 내리는 방식을 혁신하는 포괄적인 금융 분석 솔루션을 발표했다. 금융 분석 솔루션은 시장 피드부터 데이터브릭스 및 스노우플레이크와 같은 데이터 플랫폼에 저장된 내부 데이터까지 재무 데이터를 단일 인터페이스로 통합한다.
이 솔루션에는 다음과 같은 것을 포함한다.
- 금융 작업 전반에 걸쳐 다른 프론티어 모델보다 우수한 리서치 에이전트 성능을 보여주는 클로드 4
- 클로드 코드와 사용 한도가 확대된 클로드 엔터프라이즈
- 사전 구축한 MCP 커넥터: 포괄적인 시장 데이터와 비공개 시장 정보를 제공하는 금융 데이터 제공업체와 기업 플랫폼에 접근할 수 있다.
- 전문가 지원: 신속한 가치 실현을 위한 맞춤형 온보딩, 교육 및 모범 사례를 제공한다.
이 솔루션은 박스, 달루파, 데이터브릭스, 팩트셋, 모닝스타, 팔란티어, 핏치북, S&P 글로벌, 스노우플레이크 등의 다양한 데이터와 기능을 활용할 수 있다. 또한 딜로이트, KPMG, PwC, Slalom, TribeAI, Turing 등의 파트너를 통해 컨설팅 서비스와 데이터 접근 및 구현 전문성을 제공한다.
이를 활용하면 실사 및 시장 조사, 경쟁 벤치마킹 및 포트폴리오 심층 분석, 완벽한 감사 추적 기능을 갖춘 재무 모델링, 기관 수준의 투자 메모 및 투자 설명문 작성 등 중요한 투자 및 분석 워크플로우를 가속화할 수 있다는 입장이다.
앤스로픽의 주장으로는 고객사인 FundamentalLabs가 이 솔루션을 도입하여 액셀 에이전트를 구축했을 때, 재무 모델링 월드컵 대회의 7개 레벨 중 5개를 통과했으며, 복잡한 액셀 작업에서 83%의 정확도를 기록했다고 한다.
앤스로픽의 매출 책임자인 케이트 젠슨은 이는 엔터프라이즈를 위한 클로드의 맞춤형 버전이라고 하면서 ‘재무 분석가를 위해 특별히 개발되었으며, 복잡한 업무를 처리하는 데 필요한 뉘앙스, 정확성, 그리고 추론 기능을 갖추고 있다.”고 했다.
이 솔루션은 엔터프라이즈를 위한 클로드와 함께 아마존의 AWS 마켓플레이스에서 이용 가능하며 구글 클라우드 마켓플레이스에서는 곧 출시될 예정이다. 이런 솔루션으로 중소 규모 은행, 자산 관리자, 심지어 핀테크 기업조차도 대규모 내부 데이터 과학 팀을 고용하지 않고도 정교한 도구를 구축할 수 있을 것이다.
이제 기업 시장을 위해 AI 모델 제공 기업이 버티컬 모델을 제공함으로써 개인 고객이 아닌 기업 고객을 확보하기 위한 움직임이 본격화된다는 신호로 생각할 수 있다.
그 밖의 소식
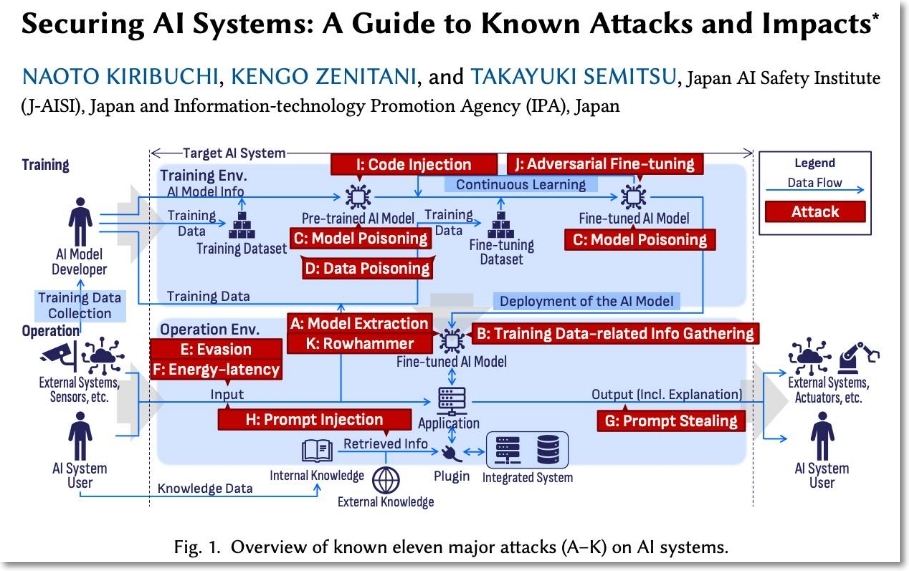
- AI 시스템에 대한 적대적 공격(Adversarial Attacks) 종류와 그 영향에 대한 아카이브 논문. 일본 AISI의 레드팀 가이드 작업의 중간 결과 같다는 것이 ETRI 전종홍 책임의 말이다. AI 보안에 대한 전문 지식이 없는 개발자, 보안 실무자, 정책 입안자들도 AI 시스템의 취약점을 쉽게 이해하고 방어할 수 있도록 하는 것이 목적이다. 논문에서는 AI 시스템에 대한 공격을 11가지 유형으로 분류하여 정의하였고, 공격 유형을 AI 시스템의 기밀성(Confidentiality), 무결성(Integrity), 가용성(Availability)을 나타내는 CIA 보안 삼각형과 연계하여 시각적으로 정리했다.
- 아마존 부서 중 RBKS(Ring 사물인터넷, Blink 보안카메라, Key 가정 배송 서비스, Sidewalk 무선 네트워크) 사업부에서는 이제 승진을 신청할 때 직원들이 AI 활용해서 얼마나 생산성이 좋아졌는지, 사례를 입증해야 한다. Ring 창업자이자 아마존 홈 시큐리티 부사장인 제이미 시미노프(Jamie Siminoff)는 “혁신적인 사고”를 장려하고 효율성 문화를 강화하기 위해 이 정책을 시행하고 있다고 밝혔다(비즈니스 인사이드, 7월 18일). 이는 새로운 트렌드를 보여주는 상황인데, 쇼피파이는 지난 4월에 관리자들이 신규 채용 전에 AI가 더 나은 성과를 낼 수 없다는 것을 입증해야 한다고 발표했다. 마이크로소프트는 일부 관리자들에게 직원들의 내부 AI 도구 사용 방식을 기준으로 직원을 평가하도록 요구하고 있다.
- 딥시크의 높은 성능이 오픈AI의 o1 모델에 ‘증류’라는 기법을 사용했기 때문이라는 이야기가 나왔었다. 퀀타 매거진의 이 글은 증류라는 기법은 이미 10년 전부터 컴퓨터 과학의 연구 주제였고 대형 기업이 자체 모델에 사용하는 기법이라는 것을 다시 밝혔다. 이 아이디어는 2015년 제프리 힌턴 교수와 3인의 구글 연구원들의 논문에서 시작했다. 구글이 BERT를 내 놓고 이를 검색에 쓰기 위해서는 BERT의 규모와 운용 비용이 많이 들기 때문에 DistillBERT를 만들어 사용하기도 했다. 450달러 미만으로 대형 모델과 유사한 수준의 모델을 만들었던 버클리의 노바스카이(NovaSky)팀의 학생 다청 리는 ‘증류는 AI의 기본 기술’이라고 한다. 처음 딥시크가 나왔을 때 국내 언론에서 딥시크가 증류라는 혁신적 기술, 놀라운 방식을 사용했다고 했을 때 모든 AI 전문가들이 씁쓸하게 웃은 이유가 이 것이다.
- 트럼프의 백악관은 다양성, 형평성, 포용성을 추구하는 소위 ‘깨어난(Woke) AI’ 모델을 갖고 있는 기업을 표적으로 삼는 행정명령을 준비 중이라고 한다(월 스트리트 저널, 7월 17일). 이 명령은 연방 계약을 맺은 AI 기업이 AI 모델에서 정치적으로 중립적이고 편견이 없어야 한다는 것을 명시할 것이며 이는 진보적 편견이 있다는 모델에 맞서기 위함이다. 모든 주요 기술 회사가 자사의 AI 도구를 연방 정부에서 사용하기 위해 경쟁하고 있기 때문에 이 명령은 광범위한 영향을 미칠 수 있으며 개발자들이 자신의 모델을 개발하는 방법에 대해 매우 조심하도록 강요할 수 있다. 이 행정명령은 이번 주에 발표될 것으로 예상되는 여러 행정명령 중 하나로, 중국과의 AI 경쟁에서 승리하기 위한 트럼프 대통령의 비전을 담고 있다고 말한다. 이 명령이 나오면 가장 영향을 받을 기업으로 앤스로픽을 예상할 수 있다.
- 메타의 글로벌 대외 협력 책임자인 조엘 카플란은 자신의 링크드인에 올린 글에서 메타는 EC가 발표한 범용 AI를 위한 실천 강령에 싸인하지 않겠다고 했다. ‘이 강령은 모델 개발자에게 많은 법적 불확실성을 야기할 뿐만 아니라 AI 법의 범위를 훨씬 넘어서는 조치를 도입하고 있다.’고 하면서 유럽은 AI에 대해 잘못된 길로 가고 있다고 비판했다. 이달 초, 유럽 최대 기업 40여 곳이 유럽연합 집행위원회(EC)에 이 규정의 시행을 ‘중단’할 것을 촉구하는 서한에 서명했다고 한다.
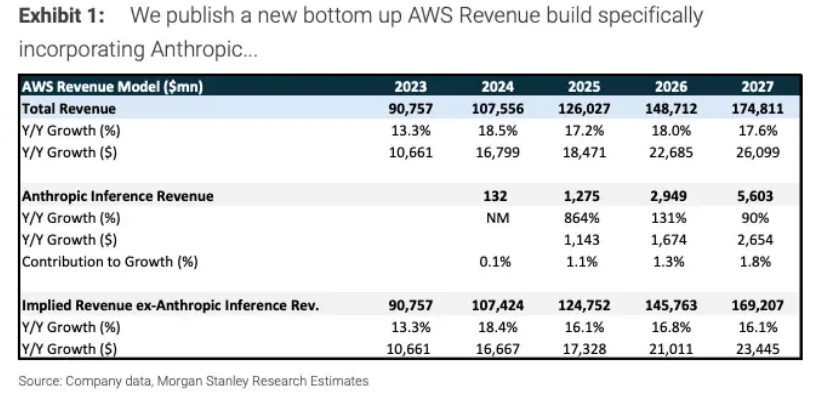
- 모건 스탠리 분석에 따르면 아마존이 앤스로픽에 투자한 후 앤스로픽이 AWS 매출에 기여하는 바가 점점 늘어나고 있다고 한다 (비즈니스 인사이더, 7월 12일). 앤스로픽에 투자한 80억 달러도 지금 가치로는 138억 달러로 평가 받는다. 2025년에 앤스로픽이 AWS 매출에 기여한 것이 12억8천만 달러이며 2026년에는 30억 달러, 2027년에는 56억 달러에 이를 것으로 본다. 앤스로픽의 총 매출은 2025년 40억 달러에서 2026년 100억 달러, 2027년에 190억 달러로 예상한다고 모건 스탠리가 예상했다. 앤스로픽의 경비 75%는 AWS 사용에 지불하고 있다.
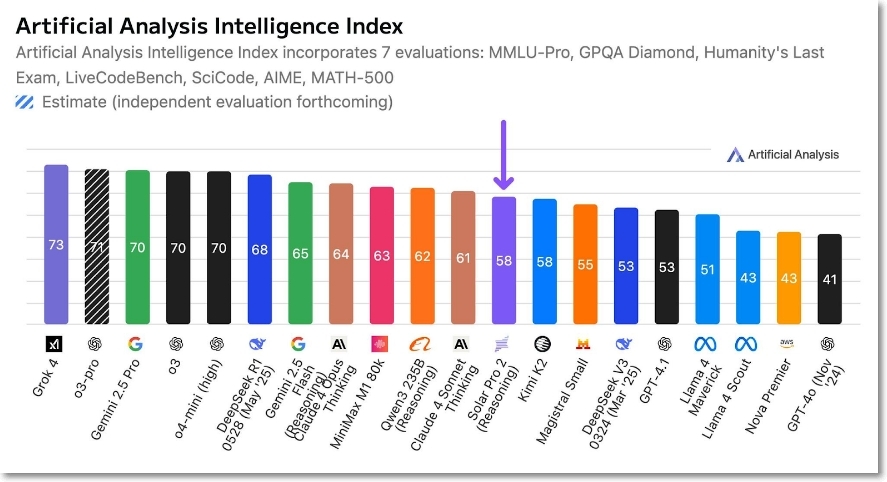
- AI 모델 평가 업체 아티피셜 애널리시스(Artificial Analysis)가 업스테이지(Upstage)의 추론 모델 ‘솔라 프로2’를 조명했다. 31B 매개변수 모델이 클로드 4 소네트(Sonnet) ‘사고’ 모드에 근접하는 인텔리전스 인덱스(intelligence index) 성능을 보여줬다고 언급했다. 얼마전에 발표한 중국 문샷의 Kimi K2에 맞먹는 평가를 받았다.
- 중국 과학원, 베이징 대학, 칭화 대학, 퀸스랜드 연구자들이 쓴 ‘LLM를 위한 컨텍스트 엔지니어링에 대한 서베이’ 논문이 나왔다. 논문에서는 기본 구성 요소, 시스템 구현, 평가 방법론, 향후 방향성으로 분류된 LLM의 컨텍스트 엔지니어링 분류법을 제공한다.
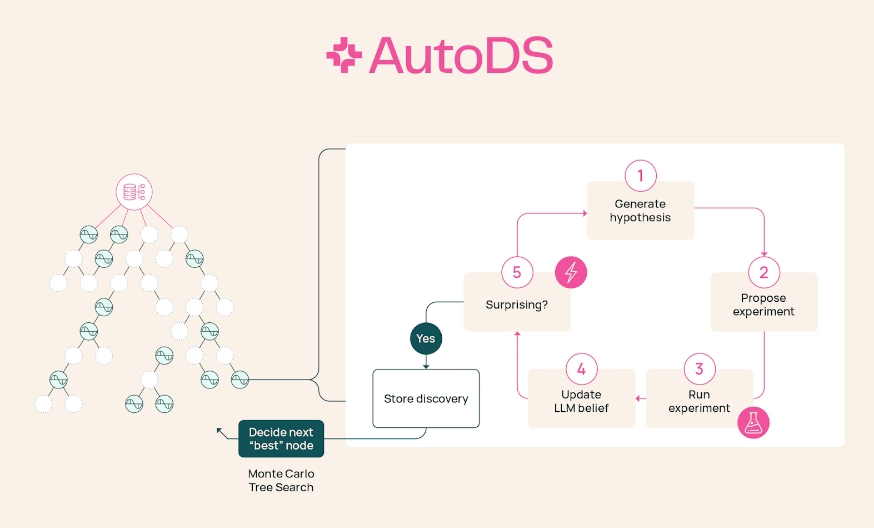
- 알렌 AI 연구소(Ai2)에서는 답을 찾기만 하는 것이 아니라 어떤 질문을 할 가치가 있는지 스스로 판단하는 AI인 AutoDS를 발표했다. LLM을 활용한 자율적이고 개방적인 과학적 발견을 위한 프로토타입 오픈소스 엔진이라고 말하는 AutoDS는 자체적인 연구 성과 측정 기준에 따라 가설을 생성하여 더욱 광범위한 탐구를 수행한다 . 이 시스템은 생성하고 수행하는 (통계적) 실험 결과를 활용하여 끝없는 프로세스 속에서 새로운 가설을 제시할 수 있다.
AutoDS는 ‘베이지안 놀라움(Surprise)’라는 새로운 접근 방식으로 이 문제를 해결하고자 하는 데, 이는 관찰자(이 경우 AutoDS의 기반이 되는 LLM)에게 발견 결과가 얼마나 “놀라운지”를 정량화하고 검색을 통해 그 놀라운 리드를 더욱 추적하도록 지시한다. 21개의 실제 데이터세트를 기반으로 평가한 결과, AutoDS는 LLM을 놀라게 하는 발견을 찾아내는 데 있어 경쟁사보다 5~29% 더 우수한 성과를 보였다. 500개 이상의 가설을 포함하는 인간 대상 연구에서는 AutoDS가 도출한 발견의 67%가 인간 평가자에게도 놀라운 결과를 보였다고 한다.