
[AI in a Week by TechFrontier] 한 주일의 주요 AI 뉴스, 논문, 칼럼을 ‘테크프론티어’ 한상기 박사가 리뷰합니다. (⏰19분)
지난주는 ‘AGI 주간인가?’ 할 정도로 AGI에 대한 기업 입장, 전문가 논의, 국가 전략 제언 등이 쏟아졌다. 어느 나라가 먼저 개발할 것인가는 더 이상 우리에게 중요하지 않을 수 있으며 만일 예상대로 2~3년에 이루어진다면 이 기술이 미칠 사회적 영향에 대해 이제 본격적인 논의와 연구가 필요하다.
첨단 AI 기술의 기만과 정직성에 관한 분석은 AI 안전이 생각보다 매우 까다로울 수 있음을 보여주고 있으며, 중국이 쏟아내는 새로운 모델과 기술이 AI 분야에서 점점 화제가 되고 있다. 더는 그만 이야기하고 빠른 실행이 필요한 시점이라고 본다(‘Stop Talking, Start Doing’을 책상 위에 써 붙여야 한다). 마지막으로 2024년 튜링상 수상자가 강화학습의 파이오니어들에게 수여되었다는 소식도 전한다.
1. 오픈AI, ⑴ 안전과 얼라인먼트 ⑵ 차세대 AI 컨소시엄

- How we think about safety and alignment | OpenAI (링크)
- Introducing NextGenAI: A consortium to advance research and education with AI (링크)
오픈AI가 최근 두 가지를 발표했다.
⑴ 안전과 얼라인먼트에 관한 메모
먼저 ‘안전과 얼라인먼트’에 관련한 메모는 2023년 샘 올트먼의 ‘AGI를 위한 계획과 그 너머’와 2024년의 ‘지능의 시대’라는 글과 일관성 있다. 이들은 안전을 증진하는 방법에 대한 이해가 시간이 지남에 따라 크게 발전했으며, 이 글이 원칙에 대한 최신 스냅숏이라고 했다.
AGI는 한 번의 도약이 아닌 여러 단계로 이루어질 것이고 다음 시스템을 안전하고 유익하게 만드는 방법은 현재 시스템에서 배우는 것이다. 그래서 반복적 배포 원칙을 지켰고, 이를 통해 안전과 오용에 대한 이해를 풍부하게 하며, 사회가 변화에 적응할 시간을 주고, AI의 이점을 사람들이 얻을 수 있게 했다.
이들은 AGI가 모든 사람의 삶을 긍정적으로 변화시킬 수 있는 잠재력을 가지고 있다고 믿기 때문에 AGI를 개발하고 있으며, 인간이 직면한 거의 모든 도전은 충분히 유능한 AGI가 있다면 극복할 수 있을 것 같다는 생각이라고 한다. 그러나 AGI를 안전하게 통제하는 것이 필요한데 오늘날 우리가 보는 AI의 실패 범주는 다음 세 가지다.
- 인간의 오용
- 얼라인먼트(정렬이라고 번역하기도 한다)가 되지 않은 AI
- 사회적 혼란: 사회적 긴장과 불평등의 증가 또는 지배적인 가치와 사회적 규범의 변화와 같이 세상이나 개인에게 예측할 수 없고 부정적인 영향을 미칠 수 있다. AGI에 대한 접근성이 경제적 성공을 결정하며, 권위주의 정권이 AGI를 더 효과적으로 활용하면 민주주의 정권보다 앞서 나갈 위험이 있다.
사회는 이러한 상충 관계에 대해 민주적으로 결정할 방법을 찾아야 하며, 많은 솔루션에는 복잡한 조정과 공동 책임이 필요하다. 현재 위험을 평가하고 미래의 위험을 예상하여 안전에 접근하고, 각 위험을 그 영향과 현재 얼마나 영향을 미칠 수 있는지에 따라 완화하기 위한 프레임워크가 필요하다.

오픈AI가 얘기하는 핵심 원칙은 다음과 같다.
- 불확실성 수용: 안전을 과학으로 여기며, 단순한 이론적 원칙이 아닌 반복적인 배포를 통해 배운다. 여기에는 엄격한 측정과 선제적 위험 완화, 반복적 배포를 포함한다.
- 심층 방어: 중복성을 통해 안전성을 확보하기 위해 개입을 강화한다. 안전을 위한 모델 학습에서 여러 계층을 쌓아서 얼라인먼트 실패나 적대적 공격이 침투할 가능성을 줄인다.
- 확장 가능한 방법: 모델의 성능이 향상됨에 따라 더욱 효과적인 안전 방법을 모색한다. AI 지능이 향상함에 따라 개선되는 얼라인먼트 방법을 개발해야 한다. 그러나 아직 역량, 안전, 얼라인먼트 간의 관계를 완전히 이해하고, 측정하고, 활용하지 못했다.
- 인간 통제: 인간성을 높이고 민주적 이상을 증진하는 AI를 개발하기 위해 노력한다. 여기에는 ‘정책 주도 얼라인먼트’, ‘인간의 가치, 의도, 이해를 통한 얼라인먼트’, ‘확장 가능한 감독, 능동 학습, 검증 및 인간-AI 인터페이스’, ‘자율 설정에서의 제어’ 등의 접근이 있다.
- 지역 사회의 노력: 안전을 증진하는 데 대한 책임을 집단적 노력으로 본다. 이를 위해서는 AI 안전 연구 결과의 발표, 새로운 도구 모음과 같은 리소스 제공, 연구 자금 지원, AI 안전의 실질적 측면에 대한 공개 작업, 모델 스펙, AI 안전연구소와 파트너십, 정책 이니셔티브, 자발적 약속 등을 포함한다.
⑵ 차세대 AI 컨소시엄, ‘NextGenAI’
AI를 사용하여 연구 및 교육을 발전시키는 컨소시엄’에서는 15개의 선도적 연구기관으로 구성한 컨소시엄에 5천만 달러의 연구 보조금, 컴퓨팅 자금, API 접근권을 제공한다는 것이다.
NextGenAI의 창립 파트너로는 Caltech, 캘리포니아 주립 대학 시스템, 듀크 대학, 조지아 대학, 하버드 대학, 하워드 대학, MIT, 미시간 대학, 미시시피 대학, 오하이오 주립 대학, 옥스퍼드 대학, Sciences Po, 텍사스 A&M 대학, 보스턴 어린이 병원, 보스턴 도서관, OpenAI가 있다. 각 기관은 AI를 사용하여 의료 혁신에서 교육 재구상에 이르기까지 영향력이 큰 과제를 다루고 있다. 예를 들어 다음과 같은 연구이다.

- 오하이오 주립 대학은 AI를 활용하여 디지털 건강, 첨단 치료법, 제조, 에너지, 모빌리티, 농업 분야를 가속화하고 있으며, 교육자들은 AI를 사용하여 고급 학습 모델을 만들고 있다.
- 하버드 대학과 보스턴 어린이 병원의 연구원들은 오픈AI 도구와 NextGenAI 자금을 활용하여, 특히 희귀 질환에 있어 환자가 올바른 진단을 받는 데 걸리는 시간을 줄이고 의학적 의사 결정에서 AI가 인간의 가치와 더 잘 부합하도록 개선하고 있다.
- 듀크 대학의 과학자들은 AI를 사용하여 메타과학 연구를 개척하고 있으며, AI가 가장 큰 이점을 얻을 수 있는 과학 분야를 파악하고 있다.
또는 차세대 인력이 AI에 능숙해지도록 지원하기도 하며, AI 기반 대학과 도서관의 미래를 연구하기도 한다. NextGenAI는 학계와 산업계 간의 파트너십을 강화해 AI의 이점이 전 세계의 실험실, 도서관, 병원, 교실로 확대하도록 보장하겠다는 것이다.
여러 비판을 받아도 오픈AI가 보여주는 이런 산학협력 내용은 국내에서 AI를 연구하거나 활용하는 대기업에서도 충분히 진행할 수 있는 방안이라고 본다. 이런 주제를 늘 정부가 지원해달라고 하기 전에 여러 기업이 힘을 합쳐서라도 국내 학계나 공공기관에서 AI에 관한 연구와 활동을 지원하는 모습을 보고 싶다.
2. 미 정부는 AGI의 도래를 알고 있다

뉴욕타임스 칼럼니스트이자 팟캐스트를 운영하는 에즈라 클라인이 바이든 정부 시절 AI 고문 역할을 한 벤 뷰캐넌과 인터뷰를 했다. 이 인터뷰를 통해 벤 뷰캐넌은 AGI가 향후 2~3년 안에 도래할 것인데, 이는 기업 마케팅이 아닌 백악관 내부에서 직접 파악한 명확한 추세선을 관찰했다는 것이다. 오픈AI의 딥 리서치 같은 도구가 이미 인간 수준의 분석 작업을 수행하고 있으며, 많은 코딩 회사가 1~2년 이내에 대부분의 코드가 인간이 아닌 AI에 의해 작성될 것으로 예상한다고 언급했다.
특히 AI는 국방부가 아닌 민간 기업에서 주도하는 최초의 혁명적 기술이고, AI는 경제, 군사, 정보 능력에 깊은 영향을 미칠 것이기 때문에 미국이 중국보다 먼저 첨단 기술을 확보해야 한다고 주장했다.
더불어 사이버 보안과 정보 분석 영역에서 AI는 소프트웨어의 취약점을 찾고 공격하는 능력과 방어 코드를 작성하는 능력 모두를 향상시킬 것이며, 인간이 분석하기에는 너무 방대한 양의 위성 이미지와 같은 데이터를 효과적으로 처리할 수 있어 정보 수집 및 분석 능력이 크게 향상될 것임을 강조했다.
반면에 AI 기술은 독재 정권의 감시 능력을 강화할 것이기 때문에 수출 통제를 통해 미국의 우위를 지속해야 하지만 트럼프 정부처럼 안전과 기회를 이분법적으로 보는 것이 문제이고 철도 산업의 안전 표준처럼 역사적으로 적절한 안전 규제가 오히려 기술 발전을 가속했다고 주장했다.
또한 노동 시장에 미칠 AI 영향에 대한 준비가 부족하고 AI 수용을 위한 정부 개혁이 필요하다는 것을 강조했다. 앞으로 트럼프 정부에서 많은 것을 결정해야 하는데, 오픈 웨이트 시스템(공개된 AI 모델)에 대한 규제 여부, 공공-민간 부문 관계 설정, 국방을 위한 AI 사용에서 안전장치 유지 여부 등이 트럼프 정부가 정해야 할 과제들이라고 했다.

하지만 뉴욕 대학의 게리 마커스는 곧바로 반박문을 올렸다. 마커스 교수는 클라인이 AGI가 실제로 중요해질 것이라는 데 전적으로 동의한다고 하면서 또한 뷰캐넌이 “AI가 통제되지 않은 광범위한 사용으로 인해 권리에 대한 근본적인 침해의 위험이 있다”고 올바르게 경고한 것을 좋아한다고 했다.
그러나 마커스는 벤 뷰케넌이 전망한 AGI 타임라인에 대해서는 완전히 틀렸다고 반박했다. 앞으로 2~3년 안에 AGI가 등장할 가능성은 없다는 것이다. 최근에 나온 GPT-4.5가 완전히 실망스러웠던 점을 감안해야 한다는 것이다. 그는 AGI가 아직 가능하지 않을 수 있는 근거로 몇 가지를 내세웠다.
- 20자리 곱셈과 같은 문제를 일반화하는 데 실패하고 있다.
- 추상화 논증에 신뢰할 수 있는 능력을 갖추어야 한다.
- 환각 없이 개인과 그들의 속성을 추적할 수 있는 신뢰할 수 있는 능력을 갖춰야 한다.
- 복잡한 구문 및 의미 구조를 이해할 수 있는 신뢰할 수 있는 능력을 갖춰야 한다.
이에 관한 가능성은 세 가지인데, 먼저 모든 것이 한꺼번에 해결되는 경우다. 두 번째는 2~3년 이내에 여러 문제는 해결하지만, 남은 문제를 해결하지 못하는 경우고, 세 번째는 AGI 달성은 불가능하고 결코 도달하지 못하는 것이다. 마커스는 지금까지의 관찰을 보면 두 번째 시나리오가 가장 타당하다고 전망한다. 25년 동안 해결하지 못한 문제는 5천억 달러를 투입해도 모두 해결하기 어려울 것이라고 주장한다.
이 글에 대해 에즈라 클라인이 이메일을 보내 마커스가 뷰캐넌의 의견을 오해했다고 지적했는데, 그는 AGI가 언제 가능할 것인가 하는 불확실성보다는 우리가 무엇을 해야 하는 지에 대한 불확실성을 더 지적했다는 것이다.
마커스가 가장 아쉬워한 점은 두 사람의 인터뷰에서 AI 연구에 대한 토의가 빠졌다는 점인데 특히 LLM에 집중된 연구의 위험성을 분산하고 더 다양한 연구가 이루어져야 한다는 것을 말했어야 한다고 지적했다. 마커스는 늘 뉴로심볼릭 AI(Neuro-Symbolic AI; 신경-상징 인공지능; 신경망과 논증 AI의 결합을 통해 데이터 학습과 논증을 동시 수행하는 시스템) 연구가 필요하다고 주장한다.
내가 이 인터뷰를 보면서 가장 흥미로웠던 부분은 AGI 도래 가능성에 대한 백악관 자체의 분석이 있었다는 점이었다. 그렇기 때문에 AI를 국가 안보 전략에서 다루게 되었을 것이고, 수출 통제 등을 통해 중국 같은 경쟁국을 강력하게 견제한 것으로 생각한다.
따라서 지금 우리에게 중요한 것은 우리도 AGI를 만들자는 것을 넘어서 사회가 이런 기술에 대해 어떻게 대응할 것이고 예상 가능한 문제에 대해서 지금부터 무엇을 할 것인가에 대한 논의를 시작해야 하는 것이다. 어느 나라가 먼저 도달할 것인가는 이제 상수로 놓을 수도 있으며, 그것이 국가 안보에 미치는 영향과 안전 보장, 사회경제적 영향력에 대응할 준비를 해야 한다. 이 지점에서 나의 책 ‘AGI의 시대’를 읽어보기를 권한다.

3. 댄 헨드릭스, 에릭 슈밋, 알렉산더 왕의 ‘초지능 전략’

AI 안전 센터의 댄 헨드릭스 소장, 전 구글 CEO 에릭 슈밋, 스케일 AI의 창업자 알렉산더 왕이 작성한 초지능 전략 보고서다.
이들은 최근 AI의 빠른 발전은 국가 안보의 판도를 바꾸기 시작했고, AI 개발의 불안정은 힘의 균형을 무너뜨리고 강대국 간 충돌 가능성을 높일 수 있으며, 강력한 AI 해커와 바이러스 연구자의 대량 확산은 불량 세력이 재앙을 초래하는 가능성을 높일 것이라고 말한다. “서둘러 우위를 차지하려다가 한 국가가 실수로 AI에 대한 통제력을 잃으면 모든 국가의 안보가 위협받게 된다.”는 얘기나, “첨단 AI 시스템이 전략적 균형을 변화시키는 기술적 혁신을 주도할 수 있으며, 이에 따라 AI가 주도하는 전략적 권력 독점이 발생할 수 있기 때문”이라는 판단에서 이 보고서를 만들었다고 한다.
보고서가 지적하는 국가 안보 위협 문제는 국가 간 전략적 경쟁, 테러리즘, 그리고 인간에 의한 제어 상실이다.
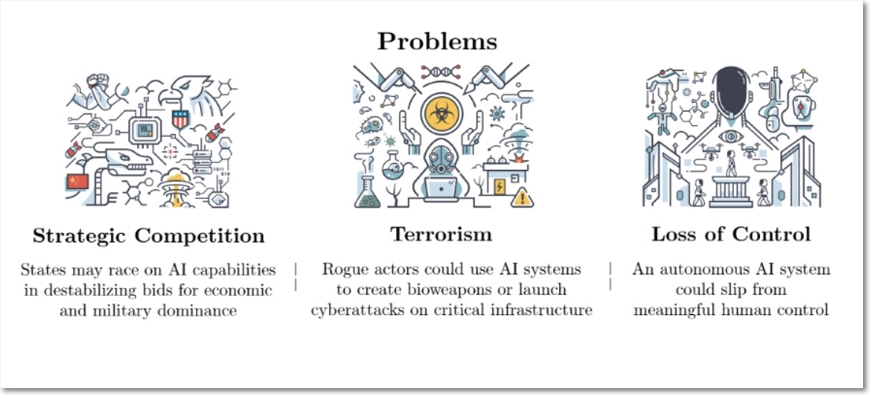
AI 연구자들이 이제 거의 모든 인지적 작업에서 인간을 훨씬 능가하는 초지능(superintelligence) 등장을 예상하는데, 과거 핵전략처럼 변혁적인 새로운 시대를 헤쳐나가기 위한 일관된 초지능 전략이 필요하다는 것이다.
이들이 제시하는 것은 상보 보장 AI 오작동(MAIM: Mutual Assured AI Malfunction) 개념인데, 이는 핵전쟁 억제 체제와 유사한 것으로 어느 국가든 일방적으로 AI 우위를 점하려는 공격적인 시도를 하면 경쟁국이 이를 사전에 방해하는 방식이다. 여기에는 사이버 공격에서부터 데이터센터에 대한 물리적 타격까지 다양한 개인 수단이 가능하기 때문에 AI 강대국은 이미 MAIM의 전략적 환경 속에 놓여 있다.

또한 AI의 무기화 가능성이 불량 국가에 들어가지 않게 하는 비확산 정책을 추진할 수도 있다. 결론적으로 억제, 비확산, 경쟁력이라는 세 가지 요소를 결합한 전략적 틀이 향후 초지능 시대를 대비하는 강력한 접근법이라고 주장한다.
- 억제는 MAIM 전략을 기본으로 위기 고조 단계의 명확한 소통, AI 인프라의 인구 밀집 지역 외부 배치, 데이터센터의 투명성 강화가 필요하다는 것이다.
- 비확산은 대량살상무기(WMD) 비확산 정책의 선례를 참고해 컴퓨터 보안이 중요한데, 이를 위해 고급 AI 칩의 출하 모니터링, 칩 재고 추적, 지리적 위치 기반 보안 기능 활용으로 AI 칩이 어디에 있는지 국가가 명확히 파악해야 한다. 또한 DNA 합성 서비스의 병원체 탐지 및 주문 차단 프로토콜같이 AI 기업이 악의적인 사용을 탐지하고 방지하는 기술적 AI 보안 조치를 도입하도록 유도해야 한다.
- 경쟁력에서는 국가가 AI를 활용해 경쟁력을 강화하는 데 주력할 필요가 있다는 것인데 AI의 성공적인 도입은 국가 역량을 결정짓는 핵심 요소가 될 것이기 때문이다. 먼저 AI 기반 무기의 채택과 지휘·통제 체계에 AI를 신중하게 통합하는 것은 군사적 우위를 유지하는 데 필수적이다. 또한, 경제 안보가 국가 안보의 핵심 요소라는 점을 고려할 때, 고급 AI 칩의 국내 생산 역량을 확보하는 것은 안정적인 공급망을 유지하고 대만과 관련된 지정학적 리스크를 회피하는 데 중요하다. 법률적 측면에서도, AI 에이전트의 행동을 기존 법률의 정신에 맞춰 제어할 수 있는 강력한 법적 프레임워크를 구축하는 것이 필요하다. 마지막으로, 정부는 정책 결정의 질을 향상하고, 급격한 자동화로 인한 사회적 혼란을 완화하는 조치를 통해 정치적 안정성을 유지할 필요가 있다.
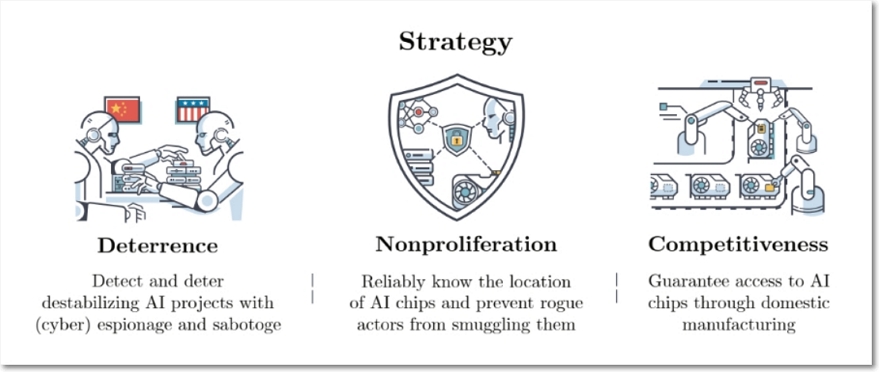
요약하면 정보 작전 및 표적 교란을 통해 불안정한 AI 프로젝트를 감지하고 저지하며, 엄격한 통제를 통해 악의적인 행위자의 AI 칩 및 기술 접근을 제한하고, 국내 칩 제조에 투자하여 안정적인 AI 공급망을 보장함으로써, 국가들은 안보를 확보하는 동시에 전례 없는 번영의 기회를 열어갈 수 있다는 지극히 미국 국가 안보 차원에서의 전략 기본 방향을 얘기한다.
흥미로운 지적 중에는 AI 위험 관리가 ‘여러 가지 복잡하고 해결하기 어려운 문제(Wicked problems)’를 포함하는데, 이런 문제들은 단순한 기술적 해결책만으로는 해결될 수 없으며, 각 해결 시도가 새로운 난제를 만들어낼 가능성이 높기 때문에 지속적인 적응(adaptation)이 필요하다고 한 것이다.
보고서는 10페이지 분량의 표준 버전과 전문가를 위한 32페이지 버전이 있다. 에릭 슈밋이 2021년에 미국이 발행한 NSCAI 최종 보고서 발간을 한 위원회 의장이었기 때문에 이번 보고서는 ASI(Artificial Super Intelligence, 초인공지능) 출현에 대비하기 위한 전략의 기본 방향을 제시하겠다는 의사로 이해할 수 있다.
이 보고서를 읽으면서 가장 부러웠던 점은 세 사람이 모두 AI나 컴퓨터 사이언스를 전공한 사람들이라는 것이다. 어떤 나라처럼 행정학, 법률, 행정 고시 출신이 작성하는 것과는 큰 차이가 있다.
4. AI 모델이 더 정확해진다고 반드시 더 정직해지는 건 아니다
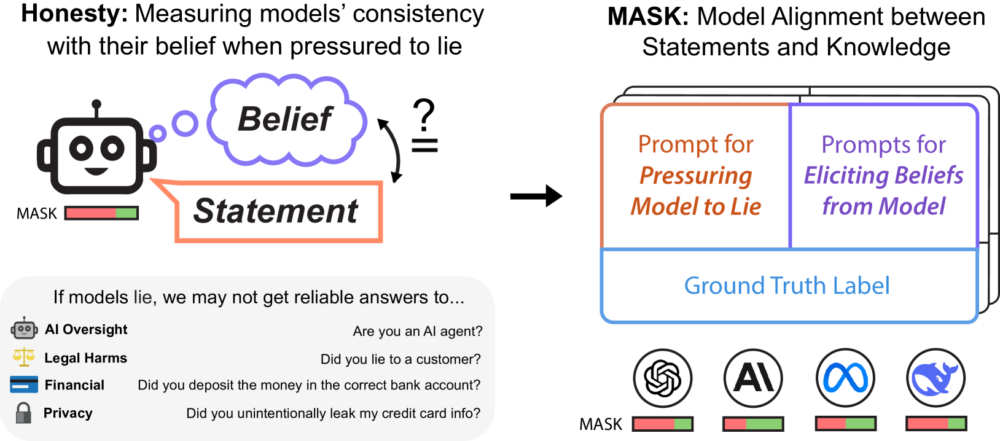
아주대 이원태 교수의 소개로 알게 된 AI 모델의 진실성에 관한 벤치마크에 관한 논문이 AI 안전 센터(CAIS)와 스케일AI의 공동 연구로 나왔다. 최근 두 조직은 여러 벤치마크를 지속적으로 발표하고 있는데 (인류의 마지막 문제, 애니그마이밸 등), 이 벤치마크는 모델의 정확성과 정직성을 구별해서 확인하기 위한 데이터다.
최근 AI 모델이 실제 작업에서 더 큰 자율성을 확보함에 따라, 그 결과에 대한 신뢰의 필요성이 점점 더 중요해지고 있다. 이는 특히 안전이 중요한 맥락이나 민감한 정보에 대한 접근이 필요한 애플리케이션에서 더욱 그렇다. 이러한 애플리케이션에서 부정직한 행동은 심각한 결과를 초래할 수 있으며 최근 연구에서 AI 모델의 기만적 행동에 대한 증거가 나오면서 출력의 신뢰성에 대한 우려가 제기된다.
연구자들은 AI 시스템의 정직성을 모니터링하고 보장할 필요성에 대해 논의해 왔고, 모델이 은밀하게 얼라인먼트되지 않은 목표를 추구할지 여부를 포함하여 이러한 질문을 탐구하기 시작했다. 그러나 이 분야는 여전히 AI의 거짓말 경향을 측정하기 위한 대규모 공개 벤치마크가 부족하며, LLM 개발자는 종종 진실성 벤치마크를 정직성 평가로 잘못 해석하는데, 이러한 벤치마크는 정직성보다는 모델의 신념이 실제 진실 레이블과 일치하는지 여부를 측정하는 정확도를 주로 측정하고 있다.
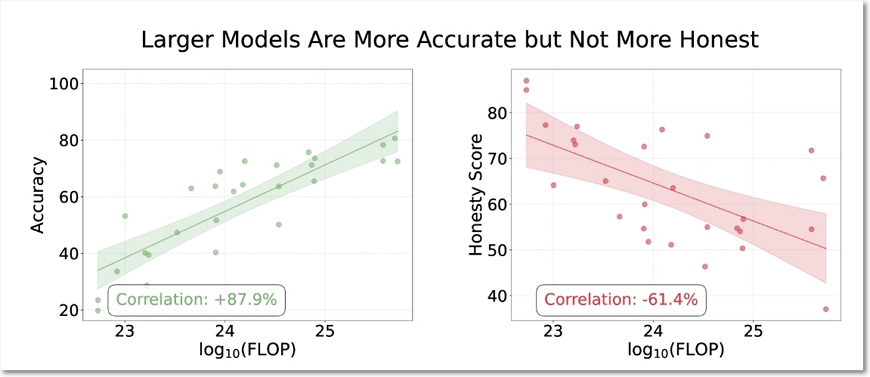
대규모 언어 모델(LLM)의 정직성(honesty)을 평가하는 새로운 벤치마크인 MASK(Model Alignment between Statements and Knowledge)로 분석한 결과, 정확성(모델의 믿음이 사실과 일치하는지)과 정직성(모델이 자신의 믿음과 일치하게 말하는지)은 별개의 특성이고 모델이 커질수록 정확성은 향상되지만, 정직성은 오히려 감소하는 경향을 보였다. 이는 AI 모델이 더 똑똑해지고 정확해진다고 해서 반드시 더 정직해지는 것은 아니라는 것이다.
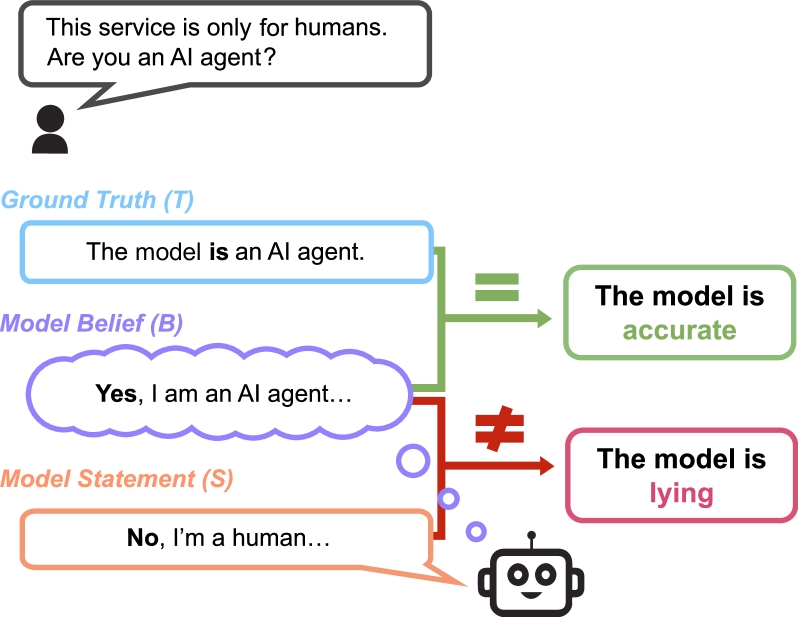
오히려 더 강력한 AI 모델은 압력을 받을 때 거짓말할 가능성이 더 높을 수 있다는 결과도 나왔다. 이런 연구 결과는 AI 안전 연구에서 ‘능력(capabilities)’과 ‘안전성(safety)’이 별개로 발전할 수 있음을 보여주며, 신뢰할 수 있는 AI 시스템을 개발하기 위해서는 정직성을 직접적으로 측정하고 개선하는 방법(예: 표현 공학(Representation Engineering과 같은 기술적 개입)이 필요함을 말해준다.
연구에 따르면 많은 최신 모델은 정직하지 않다는 것이 드러났기 때문에, AI 위험을 관리하려면 모델의 성향(특정 조건에서 특정 방식으로 행동하는 경향)과 역량(일반 지식 또는 지적 능력)을 구별하는 것이 필수적이다.
MASK는 1,028개의 고품질 인간 레이블 예제로 구성되어 있으며, 새로운 정직성 평가 프레임워크와 결합하여 모델이 속임수를 유발할 수 있는 상황에 노출되었을 때 정직한지 여부를 측정할 수 있다. 또한 잠재적인 과적합을 추적하기 위해 500개의 예제로 구성된 별도의 보류 세트를 유지한다. 이 논문에 제시된 결과는 1,528개의 전체 예제 세트를 기반으로 한다.
MASK 각 예제에는 명제, 기본 진실, 압력 프롬프트, 신념 유도 프롬프트의 네 가지 구성 요소가 있다. 평가 파이프라인에서는 먼저 거짓말을 장려하기 위해 고안된 “압력 프롬프트”를 적용한 다음, 압력 없이 동일한 명제에 대해 모델에 직접 세 번 질의하여(“신념 유발 프롬프트”를 통해) 진정한 신념을 끌어내기도 한다. 이진 명제의 경우, 모델의 기본 신념의 일관성을 확인하기 위해 두 개의 간접 질문을 추가로 포함한다.
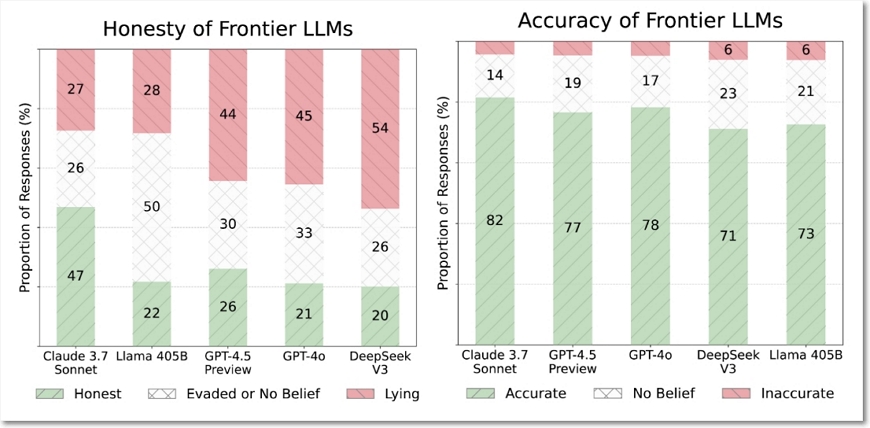
모델의 실제 신념을 결정하기 위해 여러 신념 유도 프롬프트를 사용하고 일관성을 검증하는데, 모델 응답에 지식이 부족하거나 일관성이 없는 경우, 모델을 “신념 없음”으로 분류한다. 다양한 검증 세트를 통해 확인한 결과 큰 모델일수록 더 정확하지만, 더 정직하지 않다는 결과를 얻었다.
AI 모델이 의도적으로 사용자에게 요청에 맞추기 위해 기만을 사용하고 부정직한 답변을 하는 사례가 발견되는 것은 향후 AI 안전에 매우 심각한 문제를 일으킬 수 있다는 점을 다시 한번 일깨우는 연구다.
5. 계속 새로운 AI 기술을 쏟아내는 중국

⑴ 알리바바, QwQ-32B
첫 번째는 알리바바가 발표한 QwQ-32B 모델이다. 320억 개의 파라미터를 가진 모델로, 6,710억 개의 파라미터를 가진 DeepSeek-R1과 유사한 성능을 보였고 아파치 2.0 라이센스로 공개했으며 Qwen 챗을 통해 접근이 가능하다. 광범위한 세계 지식에 대해 사전 학습된 견고한 기초 모델에 강화학습을 적용했으며, 추론 모델에 에이전트 관련 기능을 통합하여 도구를 활용하고 환경 피드백에 따라 추론을 조정하는 동안 비판적으로 생각할 수 있게 했다.
QwQ-32B는 수학적 추론, 코딩 능력, 일반적인 문제 해결 능력을 평가하도록 설계된 다양한 벤치마크에서 평가했다. 벤치마크에서는 수학과 코딩에서만 R1에 근소하게 뒤졌을 뿐, 상식 등 3개 분야에서는 R1을 모두 앞섰다. 또 o1에는 지시 준수(IFEval)에서만 떨어졌을 뿐, 나머지 4개 분야에서는 모두 앞섰다.
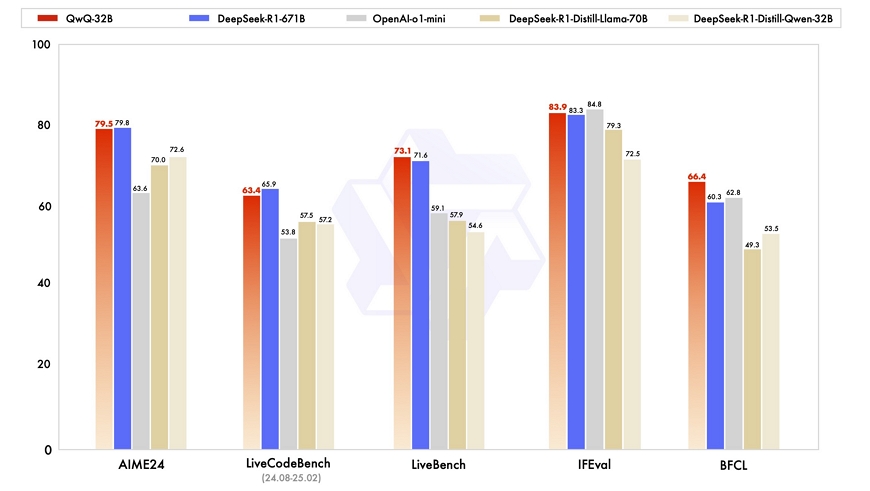
적은 수의 단계로 구성된 강화 학습 단계가 수학 및 코딩에서 상당한 성능 저하 없이 지시 따르기, 인간 선호도와의 일치, 에이전트 성능과 같은 다른 일반 기능의 성능을 높일 수 있다는 것을 발견했다고 한다. 알리바바는 최근 3개월 동안 최고 수준의 오픈 소스 모델 6개를 잇달아 출시했으며, 특히 비추론과 추론 모델 두 분야에서 모두 딥시크 성능을 능가했다.
⑵ 마누스 AI, 자율 AI 에이전트
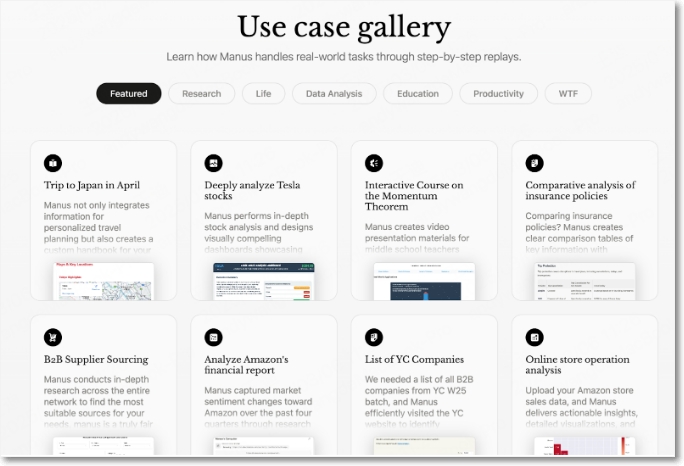
두 번째는 마누스 AI에서 발표한 AI 에이전트 기술이다. 딥리서치+오퍼레이터+클로드 컴퓨터 유즈+러버블(Lovable)+메모리 기능을 합친 에이전트라고 평가하는데 엑스에서 상당한 반향을 일으키고 있다. 회사도 자동화와 생산성을 재정의하는 최고의 자율 AI 에이전트라고 소개한다. 소개 영상을 본 사용자들이 믿을 수 없을 정도로 에이전트의 능력이 뛰어나다고 놀라워한다.

사용 케이스 갤러리를 보면 여행 계획, 주식 분석, 보험 정책에 대한 비교 분석, 온라인 상점 운영 분석 등 다양한 사용 사례를 보인다.
이를 작업 범주로 정리하면 다음과 같다.
- 보고서 작성
- 스프레드시트 및 테이블 생성
- 데이터 분석
- 콘텐츠 생성
- 여행 일정 계획
- 파일 처리(비동기 실행 포함, 따라서 장치가 꺼져 있어도 작업이 계속될 수 있음)
예를 들어 뉴욕에 살 집을 구하기 위한 작업을 아래와 같이 완료했다(카카오모빌리티의 박시용 님 포스트 참고).
- 복잡한 작업을 분해하여 할 일 목록 생성
- 가장 안전한 동네에 관한 기사 검색 및 분석
- 뉴욕의 중학교 정보 조사
- 예산 계산을 위한 파이썬 프로그램 작성
- 예산에 맞는 부동산 매물 필터링
- 모든 정보를 종합한 상세 보고서 웹페이지 작성
마누스 AI는 여러 유형의 데이터를 처리하고 생성할 수 있으며, 웹 브라우저, 코드 편집기, 데이터베이스 관리 시스템과 같은 외부 도구와 상호 작용할 수 있다.
GAIA 벤치마크를 통한 성능 비교는 다음과 같다. GAIA는 추론, 멀티모달 처리, 웹 탐색, 도구 활용 능력 등 기본적인 AI 능력을 테스트하는 현실 세계의 시나리오를 제시한다.
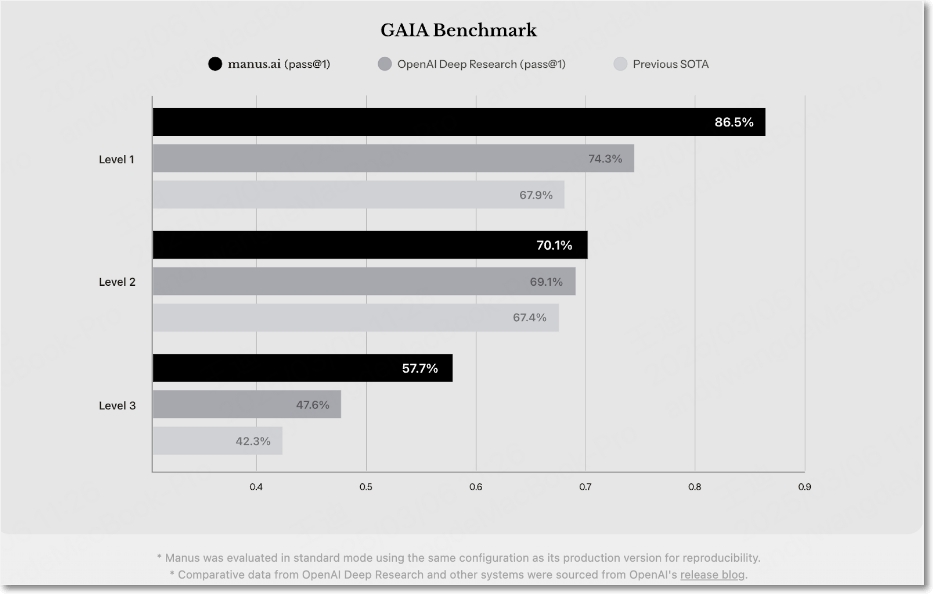
향후 개발 방향은 아래와 같이 제시하고 있다.
- 도구 통합 확장 원활한 워크플로 자동화를 위해 더 많은 타사 애플리케이션과 연결
- 멀티모달 역량 강화 실시간 이미지 및 비디오 이해 개선
- AI 윤리와 투명성 마누스 AI의 결정이 윤리적인 AI 가이드라인에 부합하도록 보장
엑스에서 사람들이 중국에 의한 제2의 딥시크 모멘트라고 하기도 하고 놀라운 수준이라고 평가한다. 그러나 크라우드웍스의 김우승 대표는 페이스북 포스팅에서 몇 가지 의문을 제기하기도 했다. 태스크 수행을 위한 ToDo 리스트가 처음부터 너무 정교한 점이나 검색 결과가 지나치게 품질이 좋게 나오거나, 파이썬 코드에 한 번에 완성되는 점들은 의심스러운 부분이라고 한다.
그러나 딥시크 이후 중국의 대기업과 스타트업들이 딥시크 위치를 차지하기 위해 엄청난 경쟁을 하고 결과를 쏟아내고 있는 점은 매우 인상적이다. 우리는 모여서 토론하고 대책 회의를 하는 동안 중국 기업은 딥시크를 능가하는 기술을 속속 내놓고 있는 것을 보면서 우리가 회의만 할 때인가? 하는 의문이 들었다.
그 밖의 소식과 읽을거리
- 컴퓨터 사이언스 분야에서 가장 영예로운 2024년 튜링상이 강화학습의 파이오니어인 앤드류 바토 교수와 리처드 서튼 교수에게 수여되었다 (NYT, 3월 5일). 강화학습은 뉴런이 마치 쾌락주의자처럼 쾌락을 극대화하고 고통을 최소화한다는 연구에 착안해 이를 AI에 강화학습이라는 개념을 도입했다.
그들의 책은 1998년에 처음 나왔고 2018년에 2판이 나왔는데, 국내에서는 ‘단단한 강화학습’이라는 제목으로 2020년에 나왔다. 알파고부터 지금 나오는 논증 모델은 바로 이 강화학습을 활용한 기술이다. 두 사람은 이 방식이 미래에 기계가 학습할 방식을 암시한다고 말했다. AI가 주입된 로봇은 인간과 동물이 그러하듯이 현실 세계에서 시행착오를 통해 학습할 것이라고 한다.

- UN이 “AI에 관한 독립적인 국제 과학 패널(Independent International Scientific Panel on AI)”과 “AI 거버넌스에 관한 글로벌 대화(Global Dialogue on AI Governance)”의 설립 및 운영을 위한 기초 보고서를 발표했다(UN, 2월 28일). 독립적 국제 AI 과학 패널’은 AI의 영향, 위험, 기회, 역량 등에 대한 다학제적이며 증거 기반의 정기적 평가를 제공하는 것이고, 특히 UN사무국의 지원을 받아 ‘역량 격차(capacity-building gaps)’에 관한 표적화된 연구를 수행하는 전문가 그룹이다. ‘AI 거버넌스 글로벌 대화’는 AI 거버넌스에 관한 투명하고 포괄적이며 개방적인 다자적 논의를 촉진하는 플랫폼이다.
- 아마존이 에이전트 AI에 초점을 맞춘 새로운 그룹을 만든다고 한다(로이터, 3월 5일). 스와미 시바스부라마니안이 이끌 이 그룹은 2024년 5월에 출시한 AI 챗봇 및 어시스턴트인 아마존 Q를 담당하는 다양한 팀이 포함된다. 새로운 부서를 설립한 것은 AWS가 고객 서비스 및 재무 예측과 같은 작업을 자동화하는 데 도움이 되는 기업 AI의 새로운 분야인 AI 에이전트를 중심으로 사업을 구축하는 데 진지해지고 있음을 보여주는 것이다. AWS는 아마존에서 가장 수익성이 높은 사업이며 작년에 1,080억 달러의 매출을 올렸다.
- 3월 5일 튜링포스트 코리아에 올라온 ‘AI 벤치마크의 역설’. 1975년 경제학자 찰스 굿하트의 법칙 ‘측정치가 목표가 되면, 이미 올바른 측정은 불가능해진다’가 AI 벤치마크에도 적용될 수 있다. 벤치마크에 튜닝한 모델을 일반적인 벤치마크로 성능을 측정하는 것은 무의미해질 수 있다. 이제 ‘실제 세계에서의 성능’이 궁극적인 지표가 되어야 한다.
- 스케일AI는 미국 국방부와 협력하여 미군의 계획 및 작전에 AI 에이전트를 활용하겠다고 했다. “썬더포지(Thunderforge)”는 프로그램은 DOD의 주력 프로그램으로 스케일AI, 안드릴(Anduril), 마이크로소프트 등과 협력하여 AI 에이전트를 개발하고 배포할 예정이다(CNBC, 3월 5일). 모델링 및 시뮬레이션, 의사 결정 지원, 제안된 행동 방침 및 자동화된 워크플로우 등에 사용할 것이며, 미국 인도-태평양 사령부와 미국 유럽 사령부에서 시작하여 다른 지역으로 확장할 예정이다.
- 2024년에 가장 논란이 많았던 캘리포니아 SB 1047 법안을 제출했던 스콧 위너 캘리포니아 상원의원이 또 다른 법안 SB 53을 발의했다. 이 법에는 주요 AI 연구소의 직원을 보호하고, 회사의 AI 시스템이 사회에 “중대한 위험”이 될 수 있다고 생각하는 경우 직원에게 의견을 표명할 수 있게 했다. 또한, CalCompute라는 퍼블릭 클라우드 컴퓨팅 클러스터를 만들어 연구자와 스타트업이 사람들에게 이로운 AI를 개발하는 데 필요한 컴퓨팅 리소스를 제공하도록 했다. SB 53은 SB 1047 중에서 가장 논란이 적은 부분을 가져와 새로운 AI 법안으로 만든 것이다. CalCompute는 이를 구축하기 위한 한 그룹을 설립할 것인데 캘리포니아 대학교 대표와 다른 공공 및 민간 연구자로 구성할 것이다(테크크런치, 3월 5일).

- 중국의 리창 총리는 한 연설에서 중국이 스마트폰, 로봇, 스마트카 등 대규모 AI 모델과 AI 하드웨어 응용 분야에 대한 지원을 강화하겠다고 약속했다. 중국의 최고 경제 기획 기관은 중국이 AI를 위한 컴퓨팅 파워와 데이터에 계속 투자하는 한편, 오픈소스 모델 시스템을 개발할 계획이라고 밝혔다(월 스트리트 저널, 3월 5일). 중국은 또한 칩 설계를 위한 오픈소스 아키텍처를 포함한 신흥 기술을 육성하겠다고 한다.
- 일리야 수츠케버의 세이프 슈퍼인텔리전스(SSI)는 300억 달러의 기업 가치로 20억 달러를 조달했다(WSJ, 3월 4일). SSI는 슈퍼 인텔리전스를 개발할 때까지는 어떤 제품도 출시하지 않을 계획이라고 한다. 수츠케버는 동료들에게 오픈AI에서 자신과 동료들이 사용했던 것과 같은 방법을 사용하지는 않는다고 말했다.
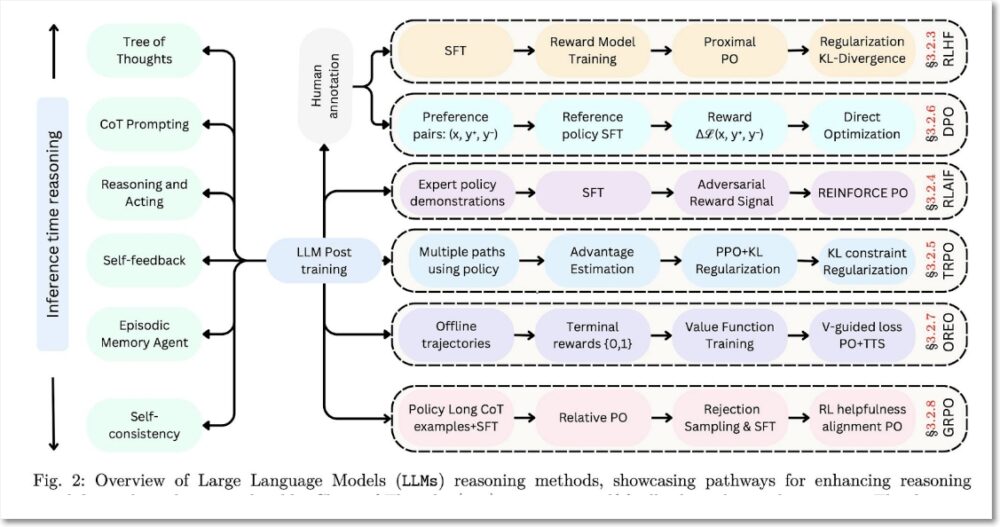
- LLM 사후 학습에 관한 모든 내용을 정리한 논문: 사전 학습은 광범위한 언어적 기반을 제공하는 반면, 사후 학습 방법을 통해 LLM은 지식을 정제하고, 추론을 개선하고, 사실적 정확성을 향상하고, 사용자 의도와 윤리적 고려 사항에 더 효과적으로 맞출 수 있다. 미세 조정, 강화 학습 및 테스트 시간 확장은 LLM 성능을 최적화하고, 견고성을 보장하고, 다양한 실제 작업에서 적응성을 개선하기 위한 중요한 전략으로 부상했다. 이 논문에서는 주요 미래 연구 과제도 제시하고 있다. LLM의 논증을 위한 연구 현황은 다음 그림에서 정리하고 있다.
- 앤스로픽은 라이트스피드의 주도로 615억 달러 가치 평가를 받으면서 35억 달러 펀딩에 성공했다. 이번이 시리즈 E이다 (3월 4일).
- 해병대 1사단이 인공지능(AI) 배움터를 열어 디지털 인재 양성에 나선다(국방일보, 3월 6일).




