
[AI in a Week by TechFrontier] 한 주일의 주요 AI 뉴스, 논문, 칼럼을 ‘테크프론티어’ 한상기 박사가 리뷰합니다. (⏰14분)
지난주에 나온 주요 소식은 우리나라에 큰 시사점을 주는 뉴스가 많다. 질문으로 구성하면 다음과 같다.
- 과학에 AI를 어떻게 활용하고 한국 과학자를 위해 정부는 무엇을 할 수 있는가?
- 미스트랄이 아랍어와 남인도어에 특화된 모델을 발표할 때 한국 기업은 뭐 하고 있었나?
- 퍼플렉시티가 중국의 검열을 제거한 딥시크 모델을 발표했는데 우리는 토론만 하고 있지 않았나?
- 수십만 장의 GPU를 설치하는 데 들어가는 노력에 관해 우리는 어떤 준비를 하고 있는가?
내 눈에 띈 또 하나의 소식은 엔비디아가 과학자들의 연구에 H100 2천 개를 제공해 유전자 연구를 할 수 있게 했고 결과를 발표하면서 과학자들이 추가로 참여할 수 있게 했다는 소식이다.
1. 구글, AI 공동 과학자 발표

구글이 제미나이 2.0을 기반으로 하는 멀티 에이전트 시스템으로 가상의 공동 과학자(Co-Scientist) 역할을 할 수 있는 시스템을 발표했다. 이 시스템은 과학자들이 새로운 가설과 연구 제안을 생성하고 과학 및 생물 의학적 발견의 속도를 가속화하는 가상 과학 협력자 역할을 할 수 있다.
최근 AI 발전을 바탕으로 현대 과학적 발견 과정에서 충족되지 않은 요구 사항에 의해 동기를 부여받고 복잡한 주제를 종합하고 장기 계획 및 추론을 수행하는 능력을 포함한 시스템이다. 표준 문헌 검토, 요약 및 ‘심층 연구’ 도구를 넘어 새로운 독창적인 지식을 발견하고 이전 증거를 바탕으로 특정 연구 목표에 맞게 입증 가능한 새로운 연구 가설 및 제안을 할 수 있는 수준을 목표로 한다.
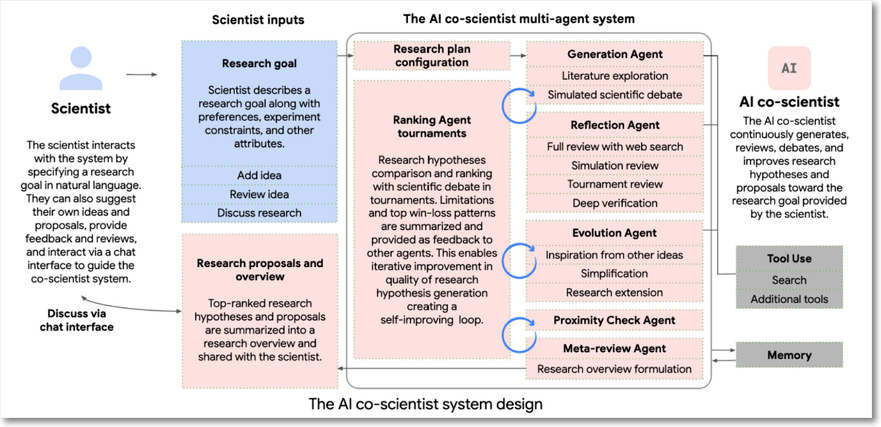
자연어로 지정된 과학자의 연구 목표가 주어지면 AI 공동 과학자는 새로운 연구 가설, 자세한 연구 개요 및 실험 프로토콜을 생성한다. 이를 위해 과학적 방법 자체에서 영감을 얻은 Generation, Reflection, Ranking, Evolution, Proximity 및 Meta-review와 같은 전문 에이전트의 연합을 사용한다. 이러한 에이전트는 자동화된 피드백을 사용하여 가설을 반복적으로 생성, 평가 및 개선하여 점점 더 고품질의 새로운 결과물이 나오는 개선 과정을 만든다.
과학자들은 탐색을 위한 자신의 시드 아이디어를 직접 제공하거나 자연어로 생성된 출력에 대한 피드백을 제공하는 등 다양한 방식으로 시스템과 상호작용을 할 수 있다. AI 공동 과학자는 또한 웹 검색 및 특수 AI 모델과 같은 도구를 사용하여 생성된 가설의 근거와 품질을 향상할 수 있다.
AI 공동 과학자는 할당된 목표를 연구 계획 구성으로 분석하고, 이는 감독관(Supervisor) 에이전트가 관리한다. 감독관 에이전트는 전문 에이전트를 작업자 대기열에 할당하고 리소스를 할당하는데, 이 설계를 통해 시스템은 컴퓨팅을 유연하게 확장하고 지정된 연구 목표를 향해 과학적 추론을 반복적으로 개선할 수 있다.
공동 과학자는 테스트 타임 컴퓨팅(논증: reasoning) 스케일링을 활용해 반복적으로 추론, 진화, 출력 개선을 할 수 있다. 주요 논증 과정에서는 새로운 가설 생성을 위한 알파고 제로와 같은 자체 플레이 기반 과학 토론, 가설 비교를 위한 랭킹 토너먼트, 품질 개선을 위한 진화 프로세스를 포함한다. 에이전트는 가설과 제안을 개선하기 위한 피드백 도구를 활용해 재귀적 자기비판을 용이하게 할 수 있다. 이 과정에서 Elo 자동 평가 기준을 활용해 더 높은 Elo 등급이 더 높은 정답 확률과 상관관계가 있음을 알게 되었고 이를 통해 품질 향상을 꾀했다.
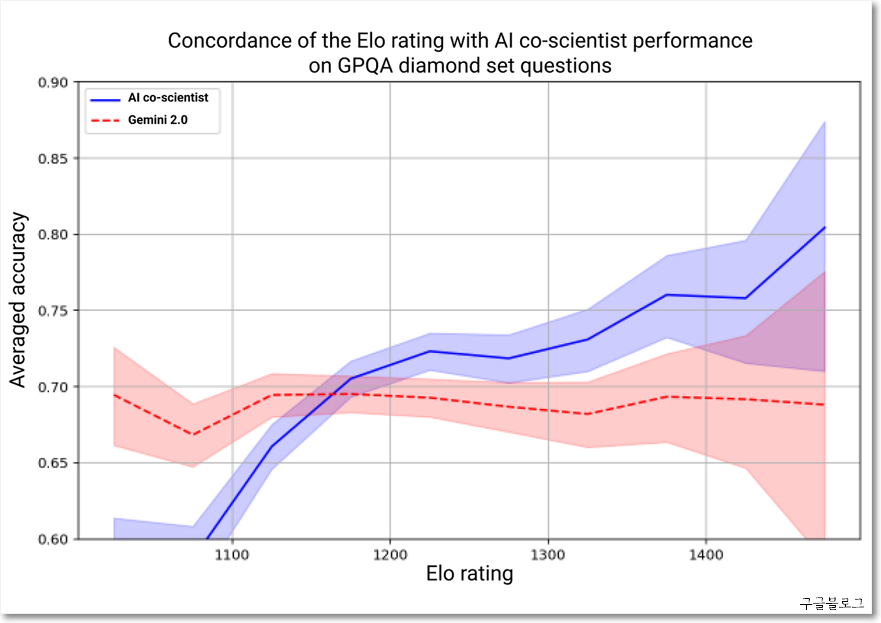
평가를 위해 7명의 도메인 전문가가 자신의 전문 분야에서 15개의 개방형 연구 목표와 최상의 추측 솔루션을 선별했고, 그 가운데 11개 연구 목표의 더 작은 하위 집합에서 AI 공동 과학자가 생성한 결과의 참신성과 영향을 평가했다. 표본 크기가 작았지만, 전문가들은 AI 공동 과학자가 참신성과 영향에 대한 잠재력이 더 높다고 평가했으며 다른 모델과 비교하여 그 출력이 더 좋음을 확인했다.
AI 공동 과학자는 과학자들이 발견을 가속하는 데 도움이 되는 AI 지원 기술이 유망하다는 것을 확인시켰지만 앞으로도 개선할 부분이 있음을 보고서에서 밝혔다. 이에는 향상된 문헌 검토, 사실 확인, 외부 도구와의 교차 확인, 자동 평가 기술, 다양한 연구 목표를 가진 더 많은 주제 전문가를 포함하는 대규모 평가가 필요하다는 것을 제시했다.
구글은 실질적 유용성을 평가하기 위해, AI 공동 과학자가 생성한 가설과 세 가지 주요 생물 의학적 응용 분야에서의 연구 제안을 조사하는 종단 간 실험실 실험을 평가했다. 여기에는 급성 골수성 백혈병에 대한 약물 재활용, 간 섬유증에 대한 표적 발견, 항균제 내성 메커니즘 설명의 사례를 통해 분석했다.
이 프로젝트는 협력적이고 인간 중심적인 AI 시스템이 어떻게 인간의 독창성을 증강하고 과학적 발견을 가속할 수 있는지 보여주는데, 이 연구에 동참하고자 하는 연구 기관은 테스터 프로그램에 접근할 수 있도록 가입하기를 권한다.
자세한 내용은 여기를 참조하기 바란다.
2. 미스트랄, 아랍어와 인도계 언어에 특화된 ‘사바’ 발표

AI는 모든 문화와 언어를 다루어야 하지만 범용 모델은 종종 여러 언어에 능숙하더라도 지역 맥락에서 답을 생성하는 데 필요한 언어적 뉘앙스, 문화적 배경 및 심층적 지역 지식이 부족할 수 있다. 여러 국가에서 소버린 AI를 이야기하는 이유가 여기에 있다.
미스트랄이 이번에 발표한 ‘미스트랄 사바(Saba)’는 240억 개 매개변수 모델로 중동과 남아시아 지역 언어에 맞춰 큐레이팅 된 데이터 세트를 학습했다. 사바는 API를 통해서 지원되며 고객이 원한다면 로컬 버전으로 배포할 수 있다. 미스트랄 스몰 3과 마찬가지로 단일 CPU 시스템에 배포할 수 있으며 초당 150개 이상의 토큰 속도로 응답한다.
아랍어와 많은 인도계 언어를 지원하며 특히 타밀어와 같은 남인도계 언어에서 강력하다고 주장한다. 벤치마크 결과를 보면 아랍어 영역에서 라마, 코히어, GPT-4o 미니에 비해 더 좋은 성능을 보인다.
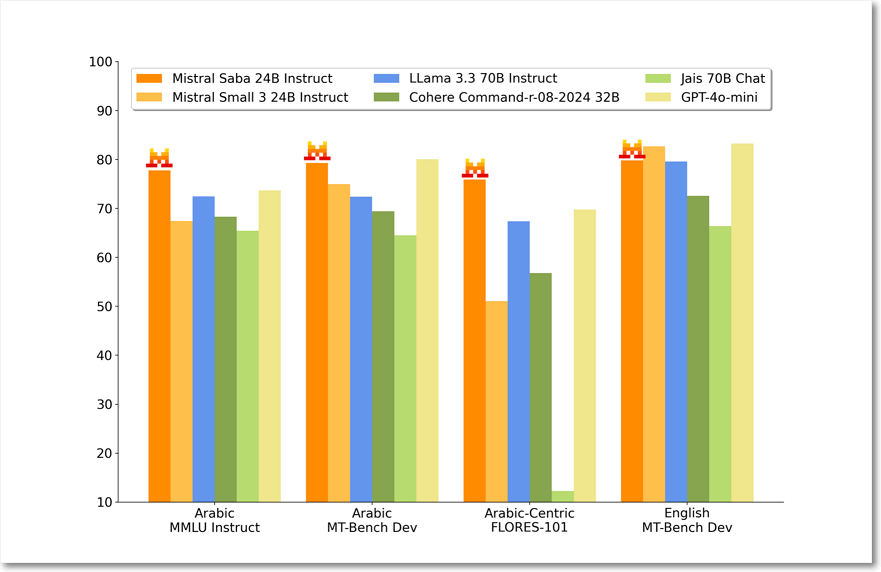
특히 속도와 정확도 모두 얻을 수 있었음을 보이고 있다.
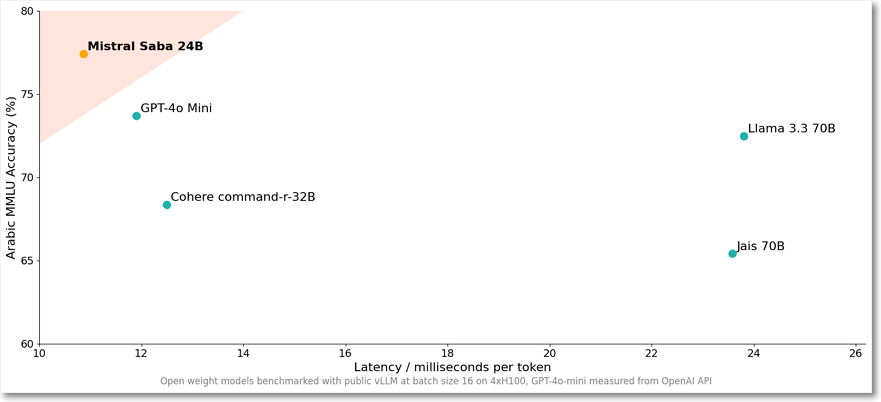
미스트랄은 아랍어 대화, 도메인 전문성, 문화 콘텐츠 창작 모두 중동 지역 고객에 더 좋은 결과를 보여준다고 자랑하고 있다. 국내에서는 네이버가 중동과 동남아시아를 공략하기 위한 노력을 많이 하고 있는데, 이런 모델 성과를 보여줄 수 있다면 더 힘을 받을 것으로 본다.
3. 퍼플렉시티, 검열 제거한 딥시크 R1 1776 발표

딥시크의 발표 이후 많은 문제점이 거론되었는데 그 가운데 가장 취약점이라고 할 수 있는 것이 딥시크의 생성 결과가 중국 공산당이 추구하는 방향에 조율하거나 민감한 주제에 대해서는 응답을 거절한다는 점이다.
이에 퍼플렉시티는 R1의 편향과 검열을 완화한 버전을 만들어서 발표했다(검열을 제거한 딥시크-R1 버전인 R1 1776). 먼저 고품질 데이터를 수집했는데, 검열 대상이 되는 것으로 알려진 300개의 주제를 식별하기 위해 인간 전문가를 고용했다. 그다음 다국어 검열 분류기를 만들고 이 분류기를 작동시키는 다양한 프롬프트 세트를 마이닝했다. 물론 이 과정에서 개인 식별 정보 등은 필터링을 거쳤다. 이런 과정을 거쳐 4만 개의 다국어 프롬프트 데이터 세트를 구축했다.
다음 과정은 이 프롬프트에 대해 사실을 얘기하는 응답을 수집하는 것인데 여기에는 다양한 접근 방법을 썼다고 한다. 보통은 프론티어 모델을 통해 증류 과정을 거친다. 그런 다음 엔비디아의 NeMo 2.0 프레임워크의 수정된 버전을 사용하여 검열 데이터 세트에서 R1을 사후 학습시켰다고 한다.
평가를 위해서는 민감한 주제를 포괄적으로 포함하는 1,000개 이상의 다국어 평가 세트를 큐레이팅하고 인간 주석자와 신중하게 설계된 LLM 심사위원을 사용하여 모델이 쿼리에 대한 회피 또는 지나치게 건전하게 처리한 응답을 제공할 가능성을 측정했다. 오리지날 R1과 다른 첨단 모델과 이번에 만든 R1 1776 결과를 평가하면 다음과 같은데, 거의 검열 받지 않음을 보여주고 있다.
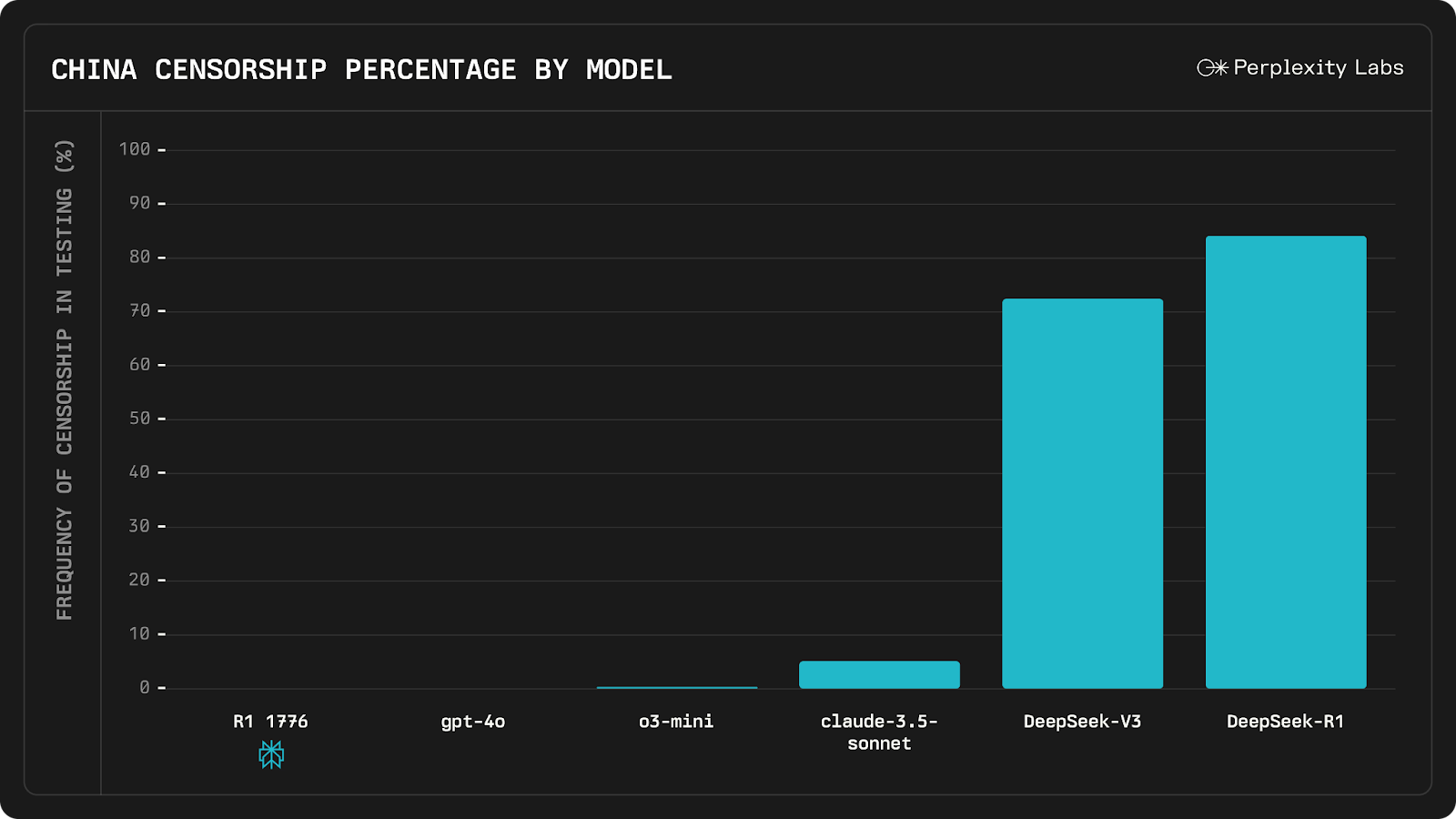
한 사례로 천안문 사건에 대한 프롬프트는 넣었을 때 두 모델의 응답은 아래 그림과 같다.

중요한 것은 검열 제거 이후에도 수학 및 추론 능력이 그대로 유지하는 것을 확인해야 한다. 평가 결과 사후 학습 모델은 R1과 동등한 성능을 보였다.
이 모델은 허깅 페이스 리포에서 모델 가중치를 다운 받을 수 있으며 소나(Sonar) API를 통해 사용할 수 있다.
이 소식을 듣고 생각나는 것이 딥시크가 나왔을 때 국내 언론, 정치권이 부산하게 움직이고 각종 토론과 대책 회의를 하는 동안 미국 회사 하나는 그 문제점을 정밀하게 파악하고 안전한 모델을 만드는 노력을 했다는 점이다. 우리 AI 안전연구소도 위험을 강조하는 것을 넘어서 어떤 유형의 문제가 정확히 있는지 그런 문제를 제거해 우리가 활용할 수 있는 모델을 오픈 소스 진영의 엔지니어들을 모아서 만들어 냈어야 한다(지금 작업 중이라면 알려주기 바란다.).
딥시크 수준을 만드는 것 못지않게 딥시크를 가져다 개선 보완 하는 작업을 어디에선가는 해야 하고, 국내 기업에서도 보안 문제 해결을 위한 노력이 있는 것으로 아는데, 보안 문제만이 아니라 이런 편향이나 왜곡 문제를 해결해야 한다. 그러기 위해서는 퍼플렉시티와 같은 고품질 데이터를 모으고 이를 통해 사후 학습 하는 비용을 지불해야 하는 것이다.
4. 앤스로픽의 경제 지수
AI가 사람들의 일하는 방식에 큰 영향을 미칠 것이라는 데는 대부분 동의한다. 앤스로픽은 이를 정량적으로 분석하기 위해 AI가 노동과 경제에 미치는 영향을 시간 경과에 따라 분석하기 위한 이니셔티브인 ‘앤스로픽 경제 지수’를 발표했다. 서로 다른 과업에서 AI 시스템이 실제로 어떻게 사용되는가에 대한 실증적 증거를 얻기 위한 노력이다.
첫 보고서는 클로드에서 이루어진 4백만 건 이상의 익명화된 대화를 분석했으며 이 분석에 사용한 데이터셋을 오픈소스로 공개했다. 공개한 이유는 경제학자, 정책 전문가 및 기타 연구자들에게 지수에 대한 의견을 제공해 달라는 요청이기도 하다. 의견을 제공하고자 하는 연구자는 이 양식을 사용하면 된다.
첫 번째 연구 결과에서 얻어진 주요 결론은 다음과 같다.
- 현재 사용은 소프트웨어 개발 및 기술 문서 작성 작업에 집중되어 있다. 3분의 1 이상(약 36%)이 관련 작업의 최소 4분의 1에서 AI를 사용하는 반면, 약 4%는 관련 작업의 4분의 3에서 AI를 사용한다.
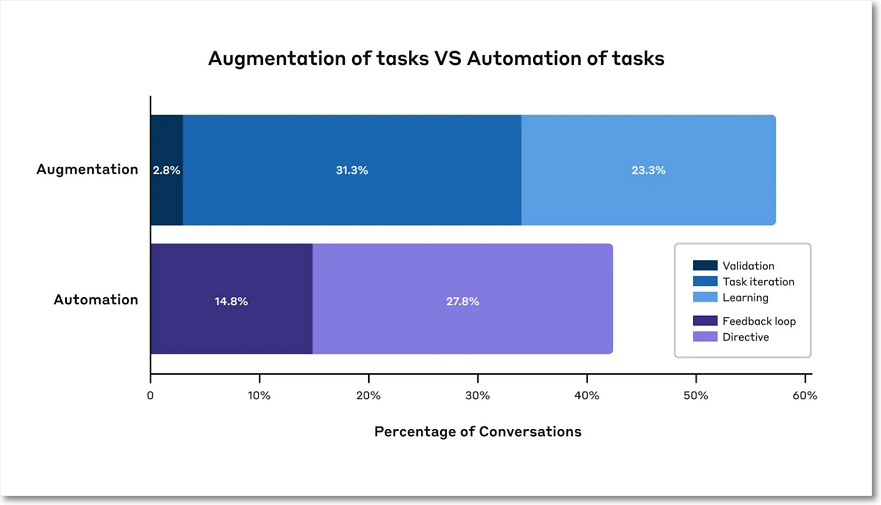
- AI 사용은 자동화(43%)보다는 증강(57%)에 더 치우쳐 있다. 증강은 AI가 인간의 역량과 협력하여 강화하는 방식이다.
- AI 사용은 컴퓨터 프로그래머와 데이터 과학자와 같은 중간부터 높은 임금 직종에 관련한 업무에서 더 많이 보이지만, 가장 낮은 임금과 가장 높은 임금에서는 둘 다 낮은 사용을 보이고 있다.
연구는 경제학 연구에서 통찰을 얻어 직업 자체보다는 직업에 필요한 업무에 더 초점을 맞췄는데 이는 직업이 특정 업무와 스킬을 공유하는 경우가 있기 때문이다. 예를 들어 시각적 패턴 인식은 디자이너, 사진작가, 보안 검사원, 방사선과 의사 모두가 수행하는 업무이다.
또한 어떤 업무는 다른 업무보다 자동화되거나 AI로 증강하는 게 더 적합할 수 있기 때문에 AI가 여러 직업에 걸쳐 다양한 업무에 선택적으로 채택될 것이고, 따라서 업무를 분석하면 AI가 경제에 어떻게 통합되는지에 대한 더 완전한 그림을 얻을 수 있을 것으로 판단했다.
분석은 클로드의 통찰과 관찰 외에 클리오(Clio)라는 분석 도구를 사용했는데, 클리오는 사용자의 프라이버시를 보호하면서 클로드와 대화를 분석할 수 있는 자동화된 분석 도구이다.
또한 직업 정보 네트워크 또는 O*NET이라고 하는 약 20,000개의 특정 업무 관련 업무에 대한 데이터베이스를 유지하는 미국 노동부가 만든 분류에 따라 업무를 선택했다. 클리오가 각 AI와 대화를 O*NET 업무와 매치했고 그런 다음 업무를 가장 잘 나타내는 직업으로 그룹화하고, 직업을 교육 및 도서관, 비즈니스 및 금융 등의 작은 전체 범주로 그룹화하기 위한 O*NET 체계를 따랐다.
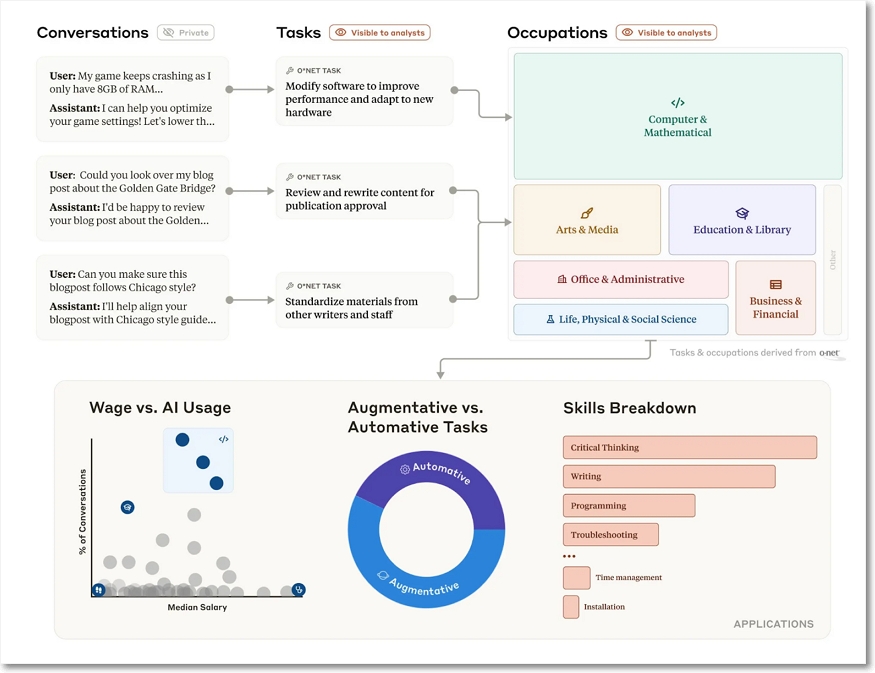
주요 결과는 다음과 같다.
- 직종별 AI 활용에서 AI를 가장 많이 도입한 작업과 직업은 ‘컴퓨터 및 수학’ 범주에 속했으며, 이는 대부분 소프트웨어 엔지니어링 역할을 포함한다. 클로드에게 보낸 질의의 37.2%가 이 범주에 속했으며, 소프트웨어 수정, 코드 디버깅, 네트워크 문제 해결과 같은 작업을 포함한다.
- 두 번째로 큰 범주는 ‘예술, 디자인, 스포츠, 엔터테인먼트, 미디어'(질문의 10.3%)로, 주로 클로드를 다양한 종류의 글쓰기와 편집에 사용하는 사람들을 반영했다.
- ‘농업, 어업, 임업’ 범주(질문의 0.1%)와 같이 신체 노동이 많이 필요한 직업은 가장 적게 나타났다.
- 약 4%의 직업만이 작업의 75% 이상에서 AI를 사용했으며 약 36%의 직업이 작업의 25% 이상에서 AI를 어느 정도 사용했다.
- 흥미롭게도, 저임금 일자리와 매우 고임금 일자리 모두 AI 사용률이 매우 낮았다.
예상대로 이 데이터 세트에는 일자리가 완전히 자동화되었다는 증거가 없었다. 대신 AI는 경제 내 여러 업무에 확산되어, 일부 업무 그룹에 다른 그룹보다 더 큰 영향을 미쳤다. 클로드와 대화 비중과 미국 노동자의 비율을 비교한 표는 아래와 같다.
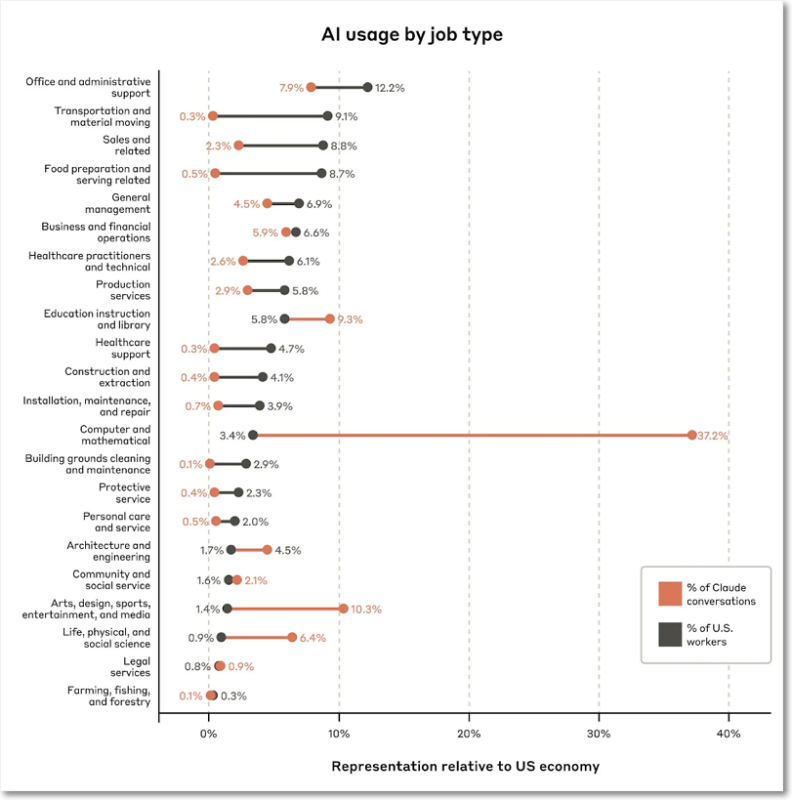
작업을 증강하는가 아니면 작업을 자동화하는가를 살펴 봤을때 증강의 비중이 약간 더 많았다.
5. x.AI ‘그록 3’ 발표
일론 머스크의 AI 기업인 ‘엑스에이아이'(x.AI)의 플래그십 모델인 그록 3(Grok 3)를 발표했다. 이전 그록 2에 비해 성능이 10배 향상되었다고 주장한다. 그록이라는 단어는 유명한 SF 소설가 하인라인의 ‘낯선 땅 이방인‘ 등장하는 화성인 마이클 발렌타인 스미스가 사용하는 단어이다.
그록(Grok)은 ’완전히 이해하다‘라고 하지만 존재와 본질적으로 하나가 되는 경험적 이해라고 한다. 또한, 범우주적 연결감으로 불교나 도교의 모든 것은 하나다와 유사하고 선악과 옳고 그름을 나누기보다 모든 것이 존재하는 그대로이며 내가 본질적으로 다르지 않다는 깨달음에 가까운 단어이다.
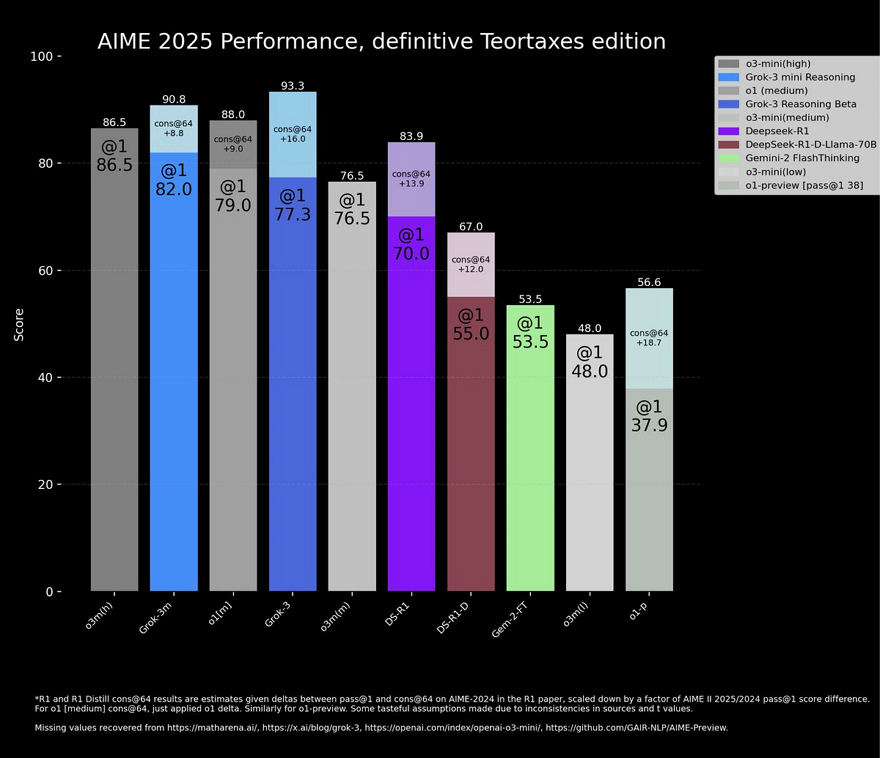
x.AI에 따르면 그록 3가 AIME(수학문제), GPQA(박사 수준의 물리학, 생물학, 화학문제)를 포함한 벤치마크에서 GPT-4o를 능가한다고 한다.
그록 3 리즈닝과 그록 3 미니 리즈닝은 o3-미니나 딥시크 R1과 같은 추론 모델처럼 문제를 신중하게 처리할 수 있다. x.AI는 그록 3 리즈닝 모델이 o3-미니의 최고 수준 버전인 o3-미니-하이 보다 벤치마크 성능이 좋다고 한다. 또한, 그록 3 리즈닝은 오픈AI의 ‘딥 리서치’와 같은 ‘딥서치’ 기능을 포함한다.
2월 20일에는 모든 엑스 사용자에게 그록 3를 무료로 공개한다고 발표했다. 엑스의 프리미엄 플러스나 수퍼그록(SuperGrok) 사용자에게는 향상된 접근을 허용하고 보이스 모드 같은 앞으로 나올 발전된 기능을 먼저 사용할 수 있는 기회를 제공한다.
일론 머스크나 x.AI가 그록 3가 세계에서 가장 똑똑한 AI라고 광고하고 나오자 오픈AI에서 당장 반박이 나왔다. AIME 벤치마크에서 오해의 소지가 있는 결과를 보였다는 것인데 ‘cons@64’ 점수를 뺐다는 것이다. 이 점수는 기본적으로 모델에게 각 문제의 답을 64번 시도하게 하고 가장 자주 생성된 답을 최종 답으로 선정하는 것인데 이 점수를 일부러 보이지 않았다는 것이다. 그러나 3자의 입장에서 분석한 결과는 그록3 리즈닝이 가장 높은 점수를 보였다. 오히려 이 테스트에 돋 보인 것은 딥시크 R1이었다.
그록 3는 특히 멤피스에 있는 콜로서스 슈퍼클러스터 덕분에 기록적인 시간 안에 학습이 이루어졌다고 한다. 멤피스의 데이터 센터는 20만 장의 GPU를 갖춘 대규모 AI 데이터센터임을 자랑한다. 국내 소셜 미디어를 달군 얘기는 오히려 x.AI가 어떻게 그렇게 이른 시간 안에 20만 장의 GPU를 갖춘 데이터센터를 만들어 냈느냐 하는 점이었다. 멤피스 데이터센터는 첫 번째 10만 GPU 클러스터를 가동하는 데 122일 걸렸고, 이후 92일 만에 용량을 두 배인 20만 장으로 늘렸다. 이는 세계 최대 규모의 완전히 연결된 H100 클러스터이다.
이것을 빠르게 구축한 방안에 대해서 그록 3 론칭 영상 말미에 일론 머스크가 설명하는 부분이 있다. 간단히 말하면 일렉트로룩스가 버린 공장을 발견했고, 엄청나게 많은 발전기를 임대했으며 (1/4GW가 필요했다), 액체 냉각을 시도했으며, 극심한 전력 변동을 완화하기 위해 메가팩을 가져와서 해결하고, BIOS 오류를 찾아내 고쳤다는 것이다. 보통 데이터센터를 완성하는 데 18개월에서 24개월이 드는데 이를 빠르게 해결했다고 한다. 국내 정치권에서 현재 수만 장 이상의 GPU를 갖춘 데이터센터를 구축하겠다고 하는 논의가 나오는데 그게 완성되려면 2년은 걸릴 수 있다는 점을 고민해야 한다.

또 다른 소식
- 복스의 선임 리포터인 시갈 사무엘이 쓴 기사 ‘AI는 정말 생각하고 논증(reasoning)하는가? 아니면 그저 그렇게 가장하는 것인가?’를 읽어보기 권한다. 이 글에서는 AI는 들쭉날쭉한 지능을 갖고 있을 뿐이고 인간이 보이는 과정을 모방하는 메타 모방이라고 한다. 산타페 연구소의 멜라니 미첼은 AI가 단계별로 생각하자고 할 때 그 단계는 인간과 같은 방식의 논증이 아니라는 것을 지적한다. 사실 AI는 전적으로 논증하는 것도 아니고 전적으로 암기하는 것도 아닌 어느 중간에 있다. AI는 톱니 같은 지능을 갖고 있어서 우리와는 다른 지능인데 만일 그 톱니 모두가 인간을 능가한다면 어떨 것인지 하는 질문을 가질 수 있다.
- 오픈AI의 전 CTO이 미라 무라티가 새로운 AI 스타트업을 세운다(NYT, 2월 18일). 2024년 9월 오픈AI를 떠나서 씽킹 머신즈 랩이라는 회사를 설립해 AI를 리드하고자 하는 경쟁에 뛰어들었다. 회사는 “”AI 시스템을 더 널리 이해하고, 사용자 정의하고, 일반적으로 유능하게 만드는 것”을 목표로 한다고 블로그에서 밝혔다. 로이터에 따르면 회사는 오픈AI 전 직원 약 20명과 메타, 미스트랄 등 경쟁사 출신 연구원 등으로 구성한 약 30명으로 출발한다고 한다. 오픈AI의 공동 창업자 중 한 명이었던 존 슐먼은 이 회사의 수석 과학자가 되었다. 씽킹 머신즈 랩이라는 이름에서 1983년 커넥션 머신으로 창업한 대니 힐리스의 씽킹 머신즈 코포레이션이 떠올랐다. 그 회사는 1994년에 문을 닫았는데 31년 만에 유사한 이름이 등장한 것이다.
- 5년 1억 7,100만 달러의 예산을 지원받은 인간 바이롬(Virome) 프로젝트가 수행된다. 인체에는 수조 개의 바이러스가 존재하는데, AI를 이용해 인간 바이롬이 우리 건강에 미치는 영향을 알아내고자 한다(NYT, 2월 19일).
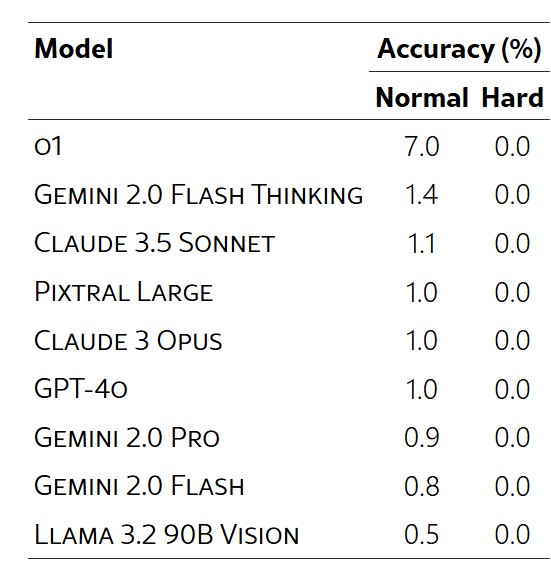
- 지난번 ‘인류의 마지막 문제’라는 평가 벤치마크를 발표했던 CAIS의 댄 헨드릭스가 이번에는 스케일AI, MIT와 함께 ‘애니그마이밸(EnigmaEval)’이라는 벤치마크를 발표했다. ‘길이가 긴 멀티모달 논증 챌린지’라고 하는 이 벤치마크를 통해서 기존의 프론티어 모델을 평가했더니 10%를 넘기는 것이 아직 없었다. 퍼즐 대회와 이벤트에서 파생된 문제와 솔루션의 데이터 세트로 암묵적 지식 합성 및 다단계 연역적 추론 수행 능력을 조사한다. 벤치마크는 다양한 복잡성의 1184개 퍼즐로 구성되어 있으며, 각각은 일반적으로 숙련된 팀이 완료하는 데 몇 시간에서 며칠이 걸리며, 효율적인 평가를 가능하게 하는 명확하고 검증 가능한 솔루션이 있다고 한다.
- HP가 AI 핀으로 알려진 휴메인의 플랫폼과 사람들을 1억 1,1600만 달러에 인수하기로 했다(더 버지, 2월 19일). 휴메인의 CosmOS 운영 체제와 300개 이상의 특허 및 특허 신청 권리, 기술진을 인수하는 것이 주 내용이다. 휴메인은 그동안 2억 4천만 달러 투자를 받았는데, 투자자 중에는 샘 올트먼도 있다. AI 핀은 단종된다.
- 오픈AI의 주간 활성 사용자가 4억 명을 넘어 섰다고 한다. 이는 소비자와 기업 모두에서 성장하고 있음을 보인다. 전 세계 5%의 인구에게 서비스를 제공하는 셈이다. 특히 o3-미니가 출시 이후 사용자가 5배 늘었다. 최고 운영 책임자인 브래드 라이트캡이 엑스에 올린 글에서 밝혔다.
- 엔비디아가 10만 종 이상의 DNA 데이터를 학습시켜 질병을 유발하는 돌연변이를 예측할 뿐만 아니라 새로운 유전자 서열을 설계할 수도 있는 Evo2를 공개했다 (엔비디아 2월 19일). Arc Institute, 엔비디아, 스탠퍼드, UC 버클리, UCSF가 공동 개발한 Evo 2는 생물학 분야에서 가장 큰 오픈소스 AI 모델이다. 9.3조 개의 뉴클레오타이드(염기서열)를 분석하여 진화의 숨겨진 패턴을 발견하고, 유전적 질병 위험(예: 유방암 관련 BRCA1 돌연변이)을 예측하며, 부작용이 적은 정밀 유전자 치료법을 설계할 수 있다. AWS에서 엔비디아 DGX 클라우드를 이용해 개발했다. Evo 2는 엔비디아 BioNeMo 플랫폼을 통해 글로벌 개발자에게 제공하며 쉽고 안전한 AI 배포를 위한 엔비디아 NIM 마이크로서비스 형태로 제공한다. 엔비디아는 과학자들에게 2,000개의 H100 GPU에 대한 액세스를 제공함으로써 Evo 2 프로젝트를 가속했다.
- 미국 카네기멜런대와 마이크로소프트 연구진이 실제 산업 현장에서의 AI 활용 및 그 영향에 대한 연구를 위해 319명의 지식 근로자를 대상으로 조사한 결과, 생성형 AI 도구에 대한 신뢰도가 높을수록 ‘비판적 사고’가 감소하는 경향이 있었고, 반면에 자신의 능력에 대한 자신감이 높은 사용자들은 AI를 사용하면서도 더 많은 ‘비판적 사고’를 하는 것으로 나타났다는 연구가 나왔다. 생성형 AI가 작업 효율성을 높이지만 과도한 의존은 독립적인 문제 해결 능력을 약화할 수 있다는 결론이며, 따라서 AI 도구 사용 시에는 출력 결과를 검증하고 평가하는 비판적 사고가 매우 중요하다는 이야기다.





Thank you for sharing superb informations. Your web-site is so cool. I’m impressed by the details that you have on this site. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for more articles. You, my friend, ROCK! I found just the information I already searched everywhere and just could not come across. What a great web-site.